Download
1 / 36
360 likes | 382 Views
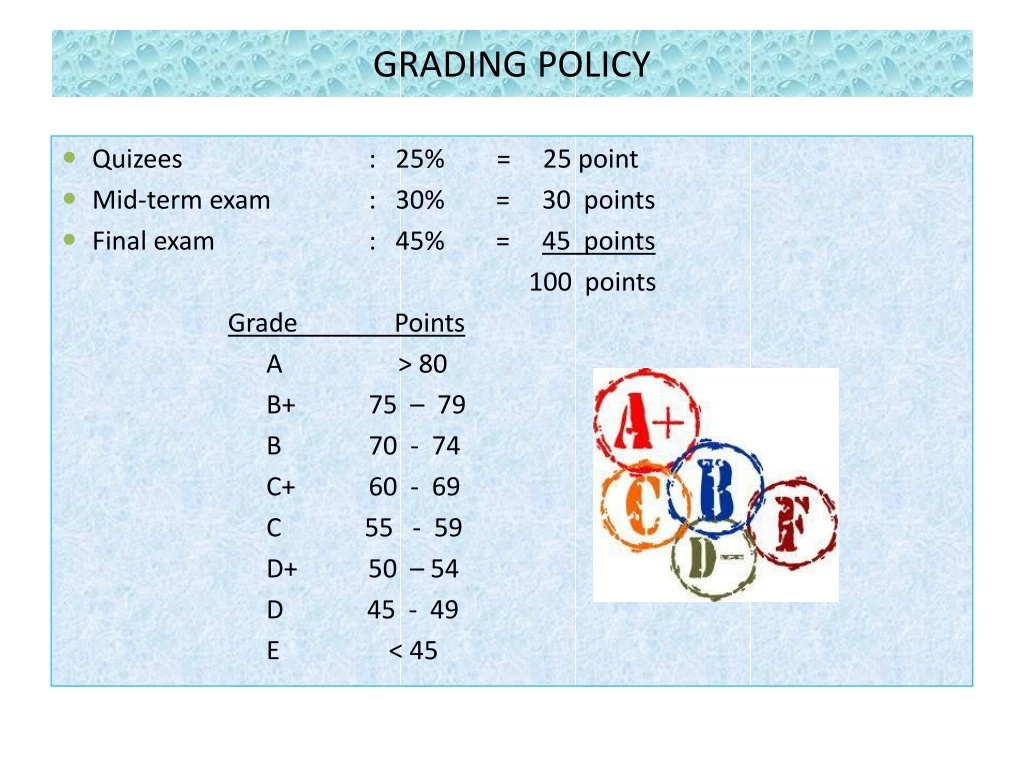
GRADING POLICY. Quizees : 25 % = 25 point Mid-term exam : 30% = 30 points Final exam : 45% = 45 points 100 points Grade Points A > 80 B+ 75 – 79 B 70 - 74 C+ 60 - 69 C 55 - 59

E N D
GRADING POLICY • Quizees : 25% = 25 point • Mid-term exam : 30% = 30 points • Final exam : 45% = 45 points 100 points Grade Points A > 80 B+ 75 – 79 B 70 - 74 C+ 60 - 69 C 55 - 59 D+ 50 – 54 D 45 - 49 E < 45
What is statisticsThe mathematics of the collection, organization, and interpretation of numerical data, especially the analysis of population characteristics byinference from sampling Why statistics • Need to make quantified statements about a phenomenon we are interested in • …Therefore we collect samples as proxies of the greater population of individuals or items that make up the phenomenon we are interested in • Anything can be expressed in statistics Aims of the course • Introduction to basic statistics • Learn to use analysis tools in EXCEL • Make you an intelligent user of data and statistics
We will bypass much of the mathematics, instead emphasizing the understanding of underlying principles Types of statistics 1. Descriptive statistics - Quantitative methods of organizing, summarizing, and presenting data in an informative way (numerically, graphically) - Describe the overall characteristics of a sample - Transform raw data into more easily understood forms 2. Inferential statistics - The branch of statistics used to make inferences about a larger population based on the data collected from a sample - Make prediction
Parametric statistics • Non parametric statistics • Primary data • Secondary data • Quantitative data • Qualitative data • Discrete data • Continuous data
Definitions • Population : all entire set of observations which we are concerned N • Sample : a smaller subset of obs. taken from population, should be drawn randomly n sampling Parameter inference statistic µ mean x σ2, S2 variance s2 • Variable : a variety of characteristic that observed • Data : all the observation ,either by counting or by measuring population sample
Parameters : summary measure that is computed to describe a characteristic of an population such as a mean or variance,represented by Greek letters. Greek letters μ , σ , σ2 • Statistic : is a summary measure that is computed to describe a characteristic from a subset English letters
Data collection Types of data /scale of measurement : • Categorical /Nominal label, identify different categories, no concept of more or less e.g. gender : male/female or moslem/hindu/other or fruit • Ordinal a set of observation ordered according to some criterion e.g ranking, test result • Interval different categories, logical order, distance between category is constant e.g. temperature (interval data can be converted into ordinal form) • Ratio interval plus meaningful zero, allows ratio comparison e.g. weight, height, etc
What do we want to know about a set of data DESCRIPTIVE STATISTICS • Shape right/left-skewed, bell-shaped bar graph (nominal/ordinal data) histogram (interval/ratio data) frequency polygon pie-chart , pictograph stem & leaf diagram box & whisker plot • Typical value measure of central tendency (x , μ) other measure of location : median, modus, quartile , decile five-number summary • Spread of scores measure of variability range the average squared distance of each score from the mean (s2) standard deviation coefficient of variation
SHAPE bar graph histogram pictograph frequency polygon pie-chart
. Histogram • Below is a grouped frequency table. It is shown (on the left) which masses went into the count for each class. We also indicated the upper bound of each class in red, to remind you that this value isn't counted in that class. • There is no space in between the bars
Frequency poligon • One way to form a frequency polygon is to connect the midpoints at the top of the bars of a histogram with line segments (or a smooth curve). The midpoints themselves could easily be plotted without the histogram and be joined by line segments. Sometimes it is beneficial to show the histogram and frequency polygon together.
A pie chart (or a circle graph) is a circularchart divided into sectors, illustrating proportion statisticians generally regard pie charts as a poor method of displaying information, and they are uncommon in scientific literature. One reason is that it is more difficult for comparisons to be made between the size of items in a chart when area is used instead of length. .
Stem & leaf diagram stem-plot • Shows the spreadness of the data whether it is right-skewed, left –skewed, or symetric (bell-shaped) • The real data is shown • The outlier can be seen • We can have back-to-back stemplot to compare two data set
MEASURE OF CENTRAL TENDENCY Mean Median The central value in an ordered set of data For an even number of values ................?
Modal Class Mode • The most commonly occurring value • For nominal data, we refer to the modal class • Not appropriate for ordinal or (usually) interval data
Box & whisker diagram/plot Boxplot is a convenient way of graphically depicting groups of numerical data through their five-number summaries: the smallest observation (sample minimum), lower quartile (Q1), median (Q2), upper quartile (Q3), and largest observation (sample maximum). A boxplot may also indicate which observations, if any, might be considered outliers. Boxplots can be drawn either horizontally or vertically
Other locations If we trim away 25% of the data on either side, we are left with the first and third quartiles • Quartile
Five-number summary : Minimum Lower quartile – Q1 Median – Q2 Upper quartile – Q3 Maximum Minimum Maximum
DATA DISTRIBUTION • Symmetric Distributions • Mean ≈ Median (approx. equal) • Skewed to the Left • Mean < Median • Mean pulled down by small values • Skewed to the Right • Mean > Median • Mean pulled up by large values Stat 111 - Lecture 3 - Numerical Summaries
SPREAD OF SCORES measure of variability(Variability refers to how "spread out" a group of scores is.) Range = max – min Variance : Standard deviation : A measure of the dispersion of a set of data from its mean. The more spread apart the data, the higher the deviation. Standard deviation is calculated as the square root of variance. s = Coefficient of variation : CV = (std. Dev / mean) *100% ratio of standard deviation and the mean
PROBABILITY P(Y) non negative0 ≤ P(Y) ≤ 1P(A) + P(not A) = 1 DISCRETE PROB. BINOMIAL PROBABILITY P(H=h) = POISSON PROBABILITY HYPERGEOMETRIC PROB P(X=x) =
CONTINUOUS PROBABILITY • Mean : µ • Variance : σ • same mean, different std dev • P(x1 < µ < X2) = P (z1 < Z < z2)
CONFIDENCE INTERVAL ESTIMATION Population Random Sample I am 95% confident that is between 40 & 60. Mean X = 50 Mean, , is unknown Sample
Confidence Intervals (σKnown - this is hardly ever true) • Assumptions • Population Standard Deviation Is Known • Population Is Normally Distributed • If Not Normal, use large samples • Confidence Interval Estimate
Shortcoming of Point Estimates ^ E.g p = 590/1000 = .59, best estimate of population proportion p BUT How good is this best estimate? A confidence interval is a range (or an interval) of values used to estimate the unknown value of a population parameter . p = , the sample proportion of x successes in a sample of size n, is the best point estimate of the unknown value of the population proportion p ^
Tool for Constructing Confidence Intervals: The Central Limit Theorem • If a random sample of n observations is selected from a population (any population), and x “successes” are observed, then when n is sufficiently large, the sampling distribution of the sample proportion p will be approximately a normal distribution. • n is large when np ≥ 15 and nq ≥ 15.
HYPOTHESIS TESTING OF THE POPULATION MEAN
FUNDAMENTAL We use samples to learn about populations We seldom observe the populations we want to know about Because we have to use samples, we engage in inference from samples to populations However, because of sampling variability, samples are not little mirror images of the population of interest. Given that samples are imperfect replications of populations, we have to use techniques such as HYPOTHESIS TESTING to determine if statements about populations are reasonable given our observed population
INTRODUCTION Objective : to determine whether the parameter is significantly different with statistic Population mean = sample mean ?
DEFINITION Hypothesis H0 : “no change” situation (hope to be disproved) H1 : statement hoped to establish Statistical test procedure in making decision : accept H0 or reject it (use for defining the hypothesis region) Types of error significance level α : 5% , 1% Direction of research hypothesis one-tailed test two-tailed test
THE STEPS IN PROBLEM SOLVING Define H0 , H1 Choose Significance level (α) Test statistic = Critical point (look at the tabel) Conclusion Interpretation based on the conclusion
EXAMPLE Main problem : A certain type of diet for obese patients is successful if after two months, on average, patients will lose more than 5 kg. At significant level 0f 5%, what is your conclusion if a sample of 50 patients shows an average of weight loss of 5.5 kg with variation of 1 kg H0 : average of weight loss = 5 H1 : average of weight loss > 5 α = 5% Z_calc = 2.357 Critical point : 1.645 Conclusion : Z calc > 1.645 H0 is rejected Interpretation : it is approved that ..........