Download

1 / 50
500 likes | 612 Views
Evolution of Hybrid DBMS. Based on: ROX: Relational Over XML [VLDB 2004] System RX: One Part Relational, One Part XML [SIGMOD 2005]. The Trend. The use of XML for representing information grows rapidly It is natural to store it natively (in XML)

E N D
Evolution of Hybrid DBMS Based on: ROX: Relational Over XML[VLDB 2004] System RX: One Part Relational, One Part XML [SIGMOD 2005]
The Trend • The use of XML for representing information grows rapidly • It is natural to store it natively (in XML) • This opens new opportunities to use it later to exchange so called business objects • The meaning behind all this is that portions of XML will have to be queried (by XQuery, for example)
The Situation Today • RDBMS (Relational DBMS) have been evolving for the past 2 decades • It is still an active research field in academics as well as in industry • SQL support is required for every system, otherwise it is hardly considered serious • An enormous commercial success • Industry-wide product developing continues
The Problem • A lot of applications today use RDBMS • The trend suggests that they will have to access information stored as XML • Rewriting an application to support XML accessing can be very expensive • Various solutions were suggested • Some of them exist today and some are predicted
Solution I • XML-Over-Relational (XOR) architecture (exists) • Classic RDBMS storage • “Shredding” XML document into a relational table
Solution I (contd.) • XQuery to SQL translation layer • Advantages: • Slight modification of existing RDBMSs
Solution I (contd.) • Disadvantages: • Problematic XQuery to SQL translation • Everything shredded incl. unused documents • Inefficient for complex queries • Some research prototypes: • LegoDB • XPeranto • ShreX
Solution II • Co-processor architecture (exists) • Classic RDBMS storage • XML documents stored as text in LOBs or VARCHARs
Solution II (contd.) • XML data opaque to RDBMS • Implies external XQuery processor: • Implemented as user-defined function • Communicates in textual format with SQL processor
Solution II (contd.) • Implemented in most commercial RDBMSs (IBM, Oracle, …) • Advantages: • Modularity of query processors • Simplicity • Disadvantages: • Loose coupling of query processors
Solution III • Side-by-Side architecture (exists) • Evolvement of XOR architecture • Tighter coupling between query processors • Inherently complex • Intermediate solution
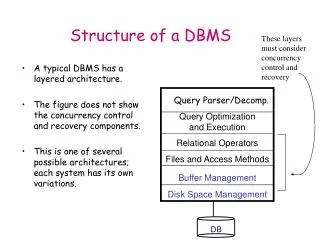
System RX – Overview • An instance of Solution III above • Developed by IBM Research Centers • Extension of DB2 UDB • Same components as in existing relational DBMS • Applications can easily migrate from relational to XML • Some components (eg. optimization) have still unresolved issues which are open for research • It is example of Hybrid System
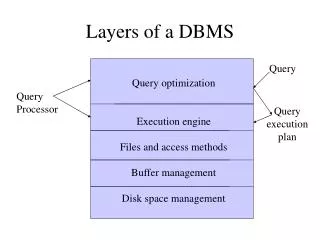
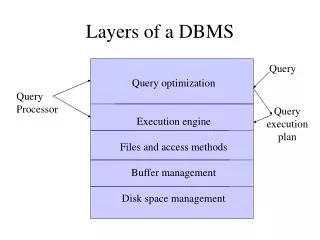
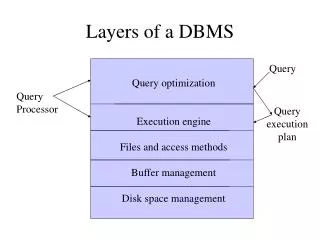
System RX – Architecture • Native XML store • Unified query model used for XQuery & SQL • XML indexes for efficient query evaluation • Relational views of XML data for relational-centric users
System RX – XML Store • XML documents stored as instances of QDM (XQuery Data Model) trees • Trees are stored in binary form with each node having pointers to children/parent • Saves repeated parsing & validation • Related nodes stored on the same page • Direct access to a page saves rootnode traversal
System RX – XML Store (contd.) • Node names & URIs are compressed into identifiers to save space • A group of XML documents are viewed as a column in relational table. The column type is XML Type: • However, instead of using LOB, Regions Index is used to reach the relevant page • SQL/XML defines functions which produce / consume the XML Type
System RX – Querying XML Data • XML-centric users use XQuery:
System RX – Querying XML Data (contd.) • Relational-centric users use SQL: XMLTable presents relational view of XML data. In this case, for each bib document it evaluates FLWOR expression. Each time returns a row which corresponds to (price, names) schema.
System RX – Querying XML Data (contd.) • Each query, either XQuery or SQL is parsed into a query graph which is an instance of an extended query-graph model (QGM) • The extended model is used to capture what is possible in SQL and XQuery – models the data flow in the query • The query graph for both of the above queries is very similar • Optimization is performed on query graph
System RX – XML Indexes • Uses 2 types of indexes: • Path Index – maps a reverse path to a path ID. Reverse path is a list of node labels from leaf to root: (name,author,book) • Value Index – maps node values to path ID • Implemented with 2 B+ trees • Special syntax for index creation • Indexes are chosen carefully to give maximal efficiency without too much storage overhead
System RX – Query Run-Time Evaluation • Extends relational query run-time evaluation to support XQuery: • XML Navigation – evaluates path & predicate expressions over XML store. Returns node references to be used by other run-time components • Index Run-time – path-indexes used to locate path IDs for given path expression. Value-indexes used to constrain only the needed paths • XQuery Functions Library
Back to: Solution IV (ROX) • ROX (Relational-Over-XML) architecture (predicted) • Evolvement of Solution III – less complex, because of a “thinner” SQL support • Native XML storage: • Documents are broken into nodes • Node information stored in B+ tree
ROX overview • The direct opposite of the XOR architecture: • XML is stored natively • XQuery: primary query & processing language • Data modeled by QDM • SQL is supported through parse-rewrite layer • Requires full implementation of XQuery engine • XQuery & QDM subsumes SQL • Implies gradual evolution (of System RX ?)
ROX overview (contd.) • Output of SQL queries is a tabular view over XML documents • Some XML rowset translation required • Implies that XML documents have schemas with sufficient homogeneity • Relational optimization depends on schema homogeneity In other words, ROX implies System RX’s infrastructure. However, SQL is no longer complements the DB, but is just an extension !
Issues with ROX • Semantic perspective of SQL to XQuery translation: • Different data models • Some differences in operational semantics • XQuery is designed for structured data manipulation • Arithmetic & boolean operators translation is easy • Normalization: • XML storage must permit normalization & de-normalization • De-normalized documents can be more efficient
Issues with ROX (contd.) • Performance • Sort order of XML tree: depth-first or breadth-first • Document structure is stored inline with data • XML index required for better efficiency • Native store allows creation of indices over XML • XML (Path) Index • Pre-calculated path expressions • Node IDs = Node references XPath expressions Node IDs
Optimization Issue • Join & predicate expressions in SQL query must be matched to XPath expression and placed in correct places • Automating this is a separate challenge • XQuery queries must also be optimized • System RX solves these tasks to some degree (XQuery optimization is a problem in System RX too)
Manageability Issue • “Google” model for DB: • Everything stored in one large heap • One index over entire heap suffices • Virtually no design • No normalization needed • An interesting approach but problematic: • Normalization is still needed • Logical boundaries required for admin purposes • Hardware performance issues impose design • Materialized views impose design
XML Wrapper • Component of IBM’s DB2 Information Integrator • Creates relational views (“nicknames”) of XML data stored in XML Store • Nickname creation syntax similar to CREATE TABLE In System RX, XML documents are represented by a column type. The ROX prototype uses a table. As if XMLTable function was already used. It means that System RX gives more flexibility for relational views over XML.
XML Wrapper (contd.) • Queries the XML in order to produce rows according to the nickname • Uses Xerces XML parser and Xalan XPath evaluator • Homogeneity plays important role • Consider: Not considered as part of the nickname!
SQL parse tree is given to the Query Optimizer Query Optimizer uses XML Wrapper to: Get alternative execution plans Get cost estimates for each plan SQL query to be evaluated: Walkthrough I
Walkthrough I (contd.) • Various execution plans: • REGION only • NATION only • Rows with REGION and NATION columns reduced by the predicate • NATION with r_regionkey as input; returns rows with an equal n_regionkey column • r_regionkey is primary_key • n_regionkey is foreign_key
Walkthrough I (contd.) • The last 2 plans are different • Each plan has a data structure associated with it • Necessary data in order to be executed later • Can be an XQuery • For example (REGION scan):
Walkthrough II • The best execution plan is fed to Query Runtime • Any data associated with the plan is fed to XML Wrapper to get rows • First request in our case: scan(REGION)
Walkthrough II (contd.) • For each row of REGION that XML Wrapper returns: • We get a value of r_regionkey, say: k • Next request: scan(NATION, k) • k references REGION element being a parent of NATION elements to return ! • These elements can be already in memory • n_count is just the number of these elements • DB2 handles the “GROUP BY” • Possibly more efficient if handled by XML Wrapper
Dataset for Experiment • Uses TPC-H dataset (http://www.tpc.org/tpch/spec/tpch2.3.0.pdf) • Benchmark dataset for business oriented queries • Consists of 8 entities (scale factor of 1): • REGION (5) • NATION (25) • SUPPLIER (~ 10 K) • PART (~ 200 K) • PARTSUPP (~ 800 K) • CUSTOMER (~ 150 K) • ORDERS (~ 1500 K) • LINEITEM (~ 6 M)
Dataset for Experiment (1-level) • Unnest (1-level nesting): one XML document per row per relational table (entity) One row from the REGION entity
Dataset for Experiment (2-level) <ORDERS> <O_ORDERKEY>123</O_ORDERKEY> <O_ORDERDATE>12-03-02</O_ORDERDATE> ... <LINEITEM> <L_ORDERKEY>123</L_ORDERKEY> <L_QUANTITY>4</L_QUANTITY> ... </LINEITEM> </ORDERS> • Nest2 (2-level nesting): • LINEITEM elements nested within correct ORDERS element • PARTSUPP nested within PART • All the rest as Unnest <PART> <P_PARTKEY>76</P_PARTKEY> <P_PARTNAME>wheel</P_PARTNAME> ... <PARTSUPP> <PS_PARTKEY>76</PS_PARTKEY> <PS_SUPPKEY>4</PS_SUPPKEY> <PS_AVAILQTY>500</PS_AVAILQTY> ... </PARTSUPP> </PART>
Dataset for Experiment (3-level) • Nest3 (3-level nesting): • LINEITEM elements nested within ORDERS elements • ORDERS elements nested within CUSTOMER elements • All the rest as Unnest • Maximal level possible <CUSTOMER> <C_CUSTKEY>99</C_CUSTKEY> <C_NAME>SomeFirm Inc.</C_NAME> ... <ORDERS> <O_ORDERKEY>123</O_ORDERKEY> <O_CUSTKEY>99</O_CUSTKEY> <O_ORDERDATE>12-03-2002</O_ORDERDATE> ... <LINEITEM> <L_ORDERKEY>123</L_ORDERKEY> <L_QUANTITY>4</L_QUANTITY> ... </LINEITEM> </ORDERS> </CUSTOMER>
Experiment Environment • 4 PowerPC processors • AIX 5.1 OS • 16 GB main memory • Data managed on 22 5 GB SCSI disks
Storage Comparison • Storage (number of disk pages used): • Native XML storage is ~5 times larger compared to relational storage of the same data • XML store uses Unicode encoding • Document structure duplicated for every record • XML data stored in text format incl. numbers • Bufferpool (disk pages stored in memory): • Under same constraint XML takes more time • Larger scale factor of dataset constraints the bufferpool (< 10%)
Queries for Experiment • TPC-H Q10 and Q22 performance compared • Q10 (customers, parts shipment problems) joins: • NATION • CUSTOMER • ORDERS • LINEITEM • Q22 (countries, customers of which have no orders and good balance), occasional join: • CUSTOMER • ORDERS Exactly the Nest3 structure !
Experiment Results • Performance of queries varies under different schemas (Unnest/Nest2/Nest3)
Analysis of Results • Nest3 – better for Q10, worst for Q22: • Q10: Saves joins • Q22: Needless reading of ORDERS & LINEITEM information for each CUSTOMER • Nest2 should be better for Q10: • XML index used to join ORDERS, LINEITEM in Unnest • XML index performs well same results for Unnest
XML Index Benefits • TPC-H Q5 used for XML Index performance comparison • Joins 6 out 8 entities • Uses all 6 of possible equi-join predicates
XML Index Benefits (contd.) • Nest2 structure saves expensive join in HashJoin • Carefully chosen index is better performance • How you select what indexes to build ? – it is an open research problem [XIST: An XML Index Selection Tool]
Conclusion • ROX prototype shows that it is possible to integrate XQuery and SQL queries. However work is still required to make it more efficient • System RX is more mature – provides better efficiency and achieves the same goal • It seems that ROX architecture is a natural evolution path of System RX • However, my opinion is that economic factors will make System RX retain full relational support for quite a long time • System RX has many things to improve in its XQuery processing, and it will