Download

1 / 17
170 likes | 293 Views
Relational Data Mining in Finance. Haonan Zhang CFWin03-37 hnzhang@cs.umanitoba.ca 03/04/2003. Organization. Motivation & Introduction Background Problem statement Solution Outcome Conclusion and future work. Motivation & Introduction.

E N D
Relational Data Mining in Finance Haonan Zhang CFWin03-37 hnzhang@cs.umanitoba.ca 03/04/2003
Organization • Motivation & Introduction • Background • Problem statement • Solution • Outcome • Conclusion and future work
Motivation & Introduction • Motivation: Analyze finance data, find and extract hidden patterns and relations between data. Thus the result will make good support for decision making in finance. • To predict financial markets is a complex and challenging task because several reasons: • The dimensionality of the problem is high. • The relationships among independent and dependent variable are weak and non-linear. • Data mining is a process that analyze data from different perspectives and explicitly show the interaction between data with a given confidence. It is suitable for predict financial markets
Motivation & Introduction cont.. • Traditional data mining methods have their limitations, such as lack of knowledge representation and limited formsof background knowledge. • The Inductive Logic Programming(ILP) and Relational Data mining (RDM) can overcome these limitations. • The ILP can naturally incorporate background knowledge andrelations between objects into the leaning process; • The RDM can discover hidden relations (general first order relations) in numerical and symbolic data using background knowledge (domain theory)
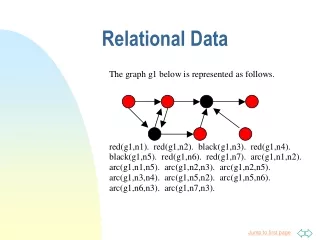
Background • A predicate is a binary function. Apredicate can be defined extensionally as a set of tuples forwhich the predicate is true, or intentionally as a set of (Horn)clauses for computing whether the predicate istrue. • A literal is a predicate or its negation • A horn clause consists of two parts: a clause head and a clausebody. A clause head isdefined as a single predicate. A clausebody is defined as a conjunction of literals.
Background cont.. • FOIL (First Order Inductive Learning) algorithm • Input: a target relationto be learned, a set of positive, a set of negative examples ofthe relation, and a set of background relations. • Learning approach: separate-and-conquer approach: It learns a clause at a time, then it remove trainingexamples covered by the clause, then begin to learn the subsequentclauses. FOIL tries to cover as much as positive training examplesand cover no negative training examples. The algorithm willterminate when all positive training examples are covered. • Output: a set of clauses that describe the target relation.
Background cont.. • The FOCL (First Order Combined Learner) algorithm extends the FOILalgorithm in several ways. • The FOCL constrains the search by using variable typing, andinter-argument constraints. • The FOCL uses background knowledge to improve the learningprocess, such as rules which are defined by a collection of examples, and a partial possible incorrect rule which is an initial approximation of the predicate to be learned.
Background cont.. • The MMDR (Machine Methodfor Discovering Regularities)algorithmfocuses on generating probabilistic first-order rules andmeasurement issues for numerical relational • MMDR permits various forms of backgroundknowledge, such as constraints, predefinedpredicates and partial (may be incorrect) rules. • MMDR uses thestatistical significance of hypotheses and the strength of datatypes scales, to limit the search space.
Problem statement • The FOIL input a target relation to be learned, a set of positiveand a set of negative examples, and a set of background knowledge. • The output would be a set of clauses that describe the targetrelation usingbackground knowledge
Solution • separate-and-conquer approach
Solution cont.. • Two kinds of literals can be appended to develop a clause. • gainful literals: literals may increase the covering ofpositive examples. Gainful literals areevaluated using information heuristic. The average information provided by discoverythat literal of the bindings is When new literalm is added, suppose that some of the bindingsare excluded, and k of then+ bindings are notexcluded. The total gain is
Solution cont.. • determinate literals: A determinate literal introduces new variable. The new partialclause has the same binding for each positive binding of currentclause, and at most one binding for each negative binding ofcurrent clause. Therefore, sometimes determinate literal has zerogain.
Solution cont.. • Four forms of literals are considered can appear in aclause:
Solution cont.. • In order to learn recursive theories without leading to infinite recursion, FOILuses three approaches to assure that the recursive literals arerisk free. • Ordering constants: the algorithm can discover an ordering of constant and order constants. • Ordering pairs of variables: when a type’s constant is ordered, the ordering of a pair of variable Vi and Vj of same type in a partial clause may also exist. • Ordering recursive literals: the ordering among variables can be extended to an ordering of literals involving a predicate and variables.
Conclusion and future work • The FOIL algorithm can effectively find the hidden relations between target relation and background knowledge and represent the target relation using background knowledge. • The FOIL algorithm uses a very complex recursive control andbackup scheme, which increase the complexity of the algorithm.Further implementation needs a better understanding of theseschemes. • Future work: implement the FOIL algorithm in parallel computers.