Download

1 / 69
690 likes | 708 Views
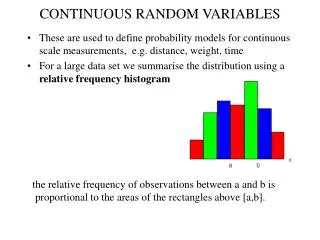
Explore models where some or all latent variables are continuous. Motivated by high-dimensional data sets, where data points lie close to a lower dimension manifold.

E N D
Continuous Latent Variables--Bishop Xue Tian
Continuous Latent Variables • Explore models in which some, or all of the latent variables are continuous • Motivation is in many data sets • dimensionality of the original data space is very high • the data points all lie close to a manifold of much lower dimensionality
Example • data set: 100x100 pixel grey-level images • dimensionality of the original data space is 100x100 • digit 3 is embedded, the location and orientation of the digit is varied at random • 3 degrees of freedom of variability • vertical translation • horizontal translation • rotation
two commonly used definitions of PCA give rise to the same algorithm Outline • PCA-principal component analysis • maximum variance formulation • minimum-error formulation • application of PCA • PCA for high-dimensional data • Kernel PCA • Probabilistic PCA
PCA-maximum variance formulation • PCA can be defined as • the orthogonal projection of the data onto a lower dimensional linear space-principal subspace • s.t. the variance of the projected data is maximized goal
PCA-maximum variance formulation red dots: data points purple line: principal subspace green dots: projected points
PCA-maximum variance formulation • data set: {xn} n=1,2,…N • xn: D dimensions • goal: • project the data onto a space having dimensionality M < D • maximize the variance of the projected data
PCA-maximum variance formulation • M=1 • D-dimension unit vector u1: the direction u1T u1=1 • xn u1Txn • mean of the projected data: • variance of the projected data: project 1 covariance matrix
PCA-maximum variance formulation • goal: maximize variance of projected data • maximize variance u1TSu1 with respect to u1 • introduce a Lagrange multiplier λ1 • a constrained maximization to prevent ||u1|| • constraint comes from u1T u1=1 • set derivative equal to zero u1: an eigenvector of S max variance: largest λ1 u1 2
PCA-maximum variance formulation • define additional PCs in an incremental fashion • choose new directions • maximize the projected variance • orthogonal to those already considered • general case: M-dimensional • the optimal linear projection defined by • M eigenvectors u1, ... ,uM of S • M largest eigenvalues λ1,...,λM
two commonly used definitions of PCA give rise to the same algorithm Outline • PCA-principal component analysis • maximum variance formulation • minimum-error formulation • application of PCA • PCA for high-dimensional data • Kernel PCA • Probabilistic PCA
PCA-minimum error formulation • PCA can be defined as • the linear projection • minimizes the average projection cost • average projection cost: mean squared distance between the data points and their projections goal
PCA-minimum error formulation red dots: data points purple line: principal subspace green dots: projected points blue lines: projection error
PCA-minimum error formulation • complete orthonormal set of basis vectors {ui} • i=1,…D, D-dimensional • each data point can be represented by a linear combination of the basis vectors • take the inner produce with uj 3 4
PCA-minimum error formulation • to approximate data points using a M-dimensional subspace - depend on the particular data points - constant, same for all data points • goal: minimize the mean squared distance • set derivative with respect to to zero j=1,…,M 5
PCA-minimum error formulation • set derivative with respect to to zero j=M+1,…,D • remaining task: minimize J with respect to ui 6 7 8
PCA-minimum error formulation • M=1 D=2 • introduce a Lagrange multiplier λ2 • a constrained minimization to prevent ||u2||0 • constraint comes from u2T u2=1 • set derivative equal to zero u2: an eigenvector of S min error: smallest λ2 u2
PCA-minimum error formulation • general case: i=M+1,…,D J: sum of the eigenvalues of those eigenvectors that are orthogonal to the principal subspace • obtain the min value of J: • select eigenvectors corresponding to the D - M smallest eigenvalues • the eigenvectors defining the principal subspace are those corresponding to the M largest eigenvalues
two commonly used definitions of PCA give rise to the same algorithm Outline • PCA-principal component analysis • maximum variance formulation • minimum-error formulation • application of PCA • PCA for high-dimensional data • Kernel PCA • Probabilistic PCA
PCA-application • dimensionality reduction • lossy data compression • feature extraction • data visualization • example PCA is unsupervised and depends only on the values xn
PCA-example • go through the steps to perform PCA on a set of data • Principal Components Analysis by Lindsay Smith • http://csnet.otago.ac.nz/cosc453/student_tutorials/principal_components.pdf
PCA-example Step 1: get data set D=2 N=10
PCA-example Step 2: subtract the mean
PCA-example Step 3: calculate the covariance matrix S S: 2x2 9
PCA-example • Step 4: Calculate the eigenvectors and eigenvalues of the covariance matrix S • the eigenvector with the highest eigenvalue is the first principle component of the data set
PCA-example • two eigenvectors • go through the middle of the points, like drawing a line of best fit • extract lines to characterize the data
PCA-example • in general, once eigenvectors are found • the next step is to order them by eigenvalues, highest to lowest • this gives us the PCs in order of significance • decide to ignore the less significant components • here is where the notion of data compression and reduced dimensionality comes
PCA-example • Step 5: derive the new data set newDataT=eigenvectorsT x originalDataAdjustT originalDataAdjustT= newData: 10x1
PCA-example • newData
PCA-example • newData: 10x2
PCA-example • Step 6: get back old data data compression • took all the eigenvectors in transformation, get exactly the original data back • otherwise, lose some information
PCA-example • newDataT=eigenvectorsT x originalDataAdjustT • newDataT=eigenvectors-1 x originalDataAdjustT • originalDataAdjustT=eigenvectors x newDataT • originalDataT=eigenvectors x newDataT + mean • take all the eigenvectors • inverse of the eigenvectors matrix is equal to the transpose of it • unit vectors
PCA-example • newData: 10x1
two commonly used definitions of PCA give rise to the same algorithm Outline • PCA-principal component analysis • maximum variance formulation • minimum-error formulation • application of PCA • PCA for high-dimensional data • Kernel PCA • Probabilistic PCA
PCA-high dimensional data • number of data points is smaller than the dimensionality of the data space N < D • example: • data set: a few hundred images • dimensionality: several million corresponding to three color values for each pixel
PCA-high dimensional data • standard algorithm for finding eigenvectors for a DxD matrix is O(D3)O(MD2) • if D is really high, a direct PCA is computationally infeasible
PCA-high dimensional data • N < D • a set of N points defines a linear subspace whose dimensionality is at most N – 1 • there is little point to apply PCA for M > N – 1 • if M > N-1 • at least D-N+1 of the eigenvalues are 0 • eigenvectors has 0 variance of the data set
PCA-high dimensional data solution: • define X: NxD dimensional centred data matrix • nth row: DxD
PCA-high dimensional data define NxN eigenvector equation for matrix • have the same N-1 eigenvalues has D-N+1 zero eigenvalues • O(D3)O(N3) • eigenvectors
two commonly used definitions of PCA give rise to the same algorithm Outline • PCA-principal component analysis • maximum variance formulation • minimum-error formulation • application of PCA • PCA for high-dimensional data • Kernel PCA • Probabilistic PCA
Kernel • Kernel function • inner product in feature space • feature space M ≥ input space N • feature space mapping is implicit mapping of x into a feature space
PCA-linear • maximum variance formulation • the orthogonal projection of the data onto a lower dimensional linear space • s.t. the variance of the projected data is maximized • minimum error formulation • the linear projection • minimizes the average projection distance linear linear
Kernel PCA • data set: {xn} n=1,2,…N • xn: D dimensions • assume: the mean has been subtracted from xn (zero mean) • PCs are defined by the eigenvectors ui of S i=1,…,D
Kernel PCA • a nonlinear transformation into an M-dimensional feature space • xn • perform standard PCA in the feature space • implicitly defines a nonlinear PC in the original data space project
original data space feature space green lines: linear projection onto the first PC nonlinear projection in the original data space
Kernel PCA • assume: the projected data has zero mean MxM i=1,…,M given , vi is a linear combination of
Kernel PCA express this in terms of kernel function in matrix notation ai: column vector i=1,…,N the solutions of these two eigenvector equations differ only by eigenvectors of K having zero eigenvalues
Kernel PCA • normalization condition for ai
Kernel PCA • in feature space: what is the projected data points after PCA
Kernel PCA • original data space • dimensionality: D • D eigenvectors • at most D linear PCs • feature space • dimensionality: M M>>D (even infinite) • M eigenvectors • a number of nonlinear PCs then can exceed D • the number of nonzero eigenvalues can not exceed N