Download

1 / 33
330 likes | 341 Views
Conditional Random Fields: Probabilistic Models. Pusan National University AILAB. Kim, Minho. x 1. x 2. x 3. X:. Birds. noun. like. verb. flowers. noun. Y:. y 1. y 2. y 3. Labeling Sequence Data Problem. X is a random variable over data sequences

E N D
Conditional Random Fields: Probabilistic Models Pusan National University AILAB. Kim, Minho
x1 x2 x3 X: Birds noun like verb flowers noun Y: y1 y2 y3 Labeling Sequence Data Problem • X is a random variable over data sequences • Y is a random variable over label sequences • Yi is assumed to range over a finite label alphabet A • The problem: • Learn how to give labels from a closed set Y to a data sequence X
Generative Probabilistic Models • Learning problem: Choose Θ to maximize jointlikelihood: L(Θ)= Σ log pΘ(yi,xi) • The goal: maximization of the joint likelihood of training examples y = argmax p*(y|x) = argmax p*(y,x)/p(x) • Needs to enumerate all possible observation sequences
Hidden Markov Model • In a Hidden Markov Model (HMM) we do not observe the sequence that the model passed through (X) but only some probabilistic function of it (Y). Thus, it is a Markov model with the addition of emission probabilities: Bik = P(Yt = k|Xt = i)
POS Tagging in HMM • Optimal sequence • Contextual probability • Lexical probability
POS Tagging in HMM • Learning(Maximum Likelihood Estimation)
HMM – why not? • Advantages: • Estimation very easy. • Closed form solution • The parameters can be estimated with relatively high confidence from small samples • But: • The model represents all possible (x,y) sequences and defines joint probability over all possible observation and label sequences needless effort
Discriminative Probabilistic Models Generative Discriminative “Solve the problem you need to solve”: The traditional approach inappropriately uses a generative joint model in order to solve a conditional problem in which the observations are given. To classify we need p(y|x) – there’s no need to implicitly approximate p(x).
Discriminative Models - Estimation • Choose Θy to maximize conditional likelihood: L(Θy)= Σ log pΘy(yi|xi) • Estimation usually doesn’t have closed form • Example – MinMI discriminative approach (2nd week lecture)
Maximum Entropy Markov Model • MEMM: • a conditional model that represents the probability of reaching a state given an observation and the previous state • These conditional probabilities are specified by exponential models based on arbitrary observation features
POS Tagging in MEMM • Optimal sequence • Joint probability
The Label Bias Problem: Solutions • Determinization of the Finite State Machine • Not always possible • May lead to combinatorial explosion • Start with a fully connected model and let the training procedure to find a good structure • Prior structural knowledge has proven to be valuable in information extraction tasks
Random Field Model: Definition • Let G = (V, E) be a finite graph, and let A be a finite alphabet. • The configuration spaceΩ is the set of all labelings of the vertices in V by letters in A. If C is a part of V and ω is an element of Ω is a configuration, the ωc denotes the configuration restricted to C. • A random field on G is a probability distribution on Ω.
Random Field Model: The Problem • Assume that a finite number of features can define a class • The features fi(w) are given and fixed. • The goal: estimating λ to maximize likelihood for training examples
Conditional Random Field: Definition • X – random variable over data sequences • Y - random variable over label sequences • Yi is assumed to range over a finite label alphabet A • Discriminative approach: we construct a conditional model p(y|x) and do not explicitly model marginal p(x)
CRF - Definition • Let G = (V, E) be a finite graph, and let A be a finite alphabet • Y is indexed by the vertices of G • Then (X,Y) is a conditional random field if the random variables Yv, conditioned on X, obey the Markov property with respect to the graph: p(Y|X,Yw,w≠v) = p(Yv|X,Yw,w~v), where w~v means that w and v are neighbors in G
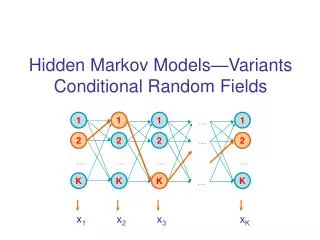
CRF on Simple Chain Graph • We will handle the case when G is a simple chain: G = (V = {1,…,m}, E={ (I,i+1) }) HMM (Generative) MEMM (Discriminative) CRF
Fundamental Theorem of Random Fields (Hammersley & Clifford) • Assumption: • G structure is a tree, of which simple chain is a private case
CRF – the Learning Problem • Assumption: the features fk and gk are given and fixed. • For example, a boolean feature gk is TRUE if the word Xi is upper case and the label Yi is a “noun”. • The learning problem • We need to determine the parameters Θ = (λ1, λ2, . . . ; µ1, µ2, . . .) from training data D = {(x(i), y(i))} with empirical distribution p~(x, y).
최대 엔트로피 모델 • 우리가 알아낸 제약 조건을 다 만족하는 확률 분포들 중에서 엔트로피가 최대가 되는 확률 분포를 취함 • 알고 있는 정보는 반영하되, 확실하지 않은 경우에 대해서는 불확실성 정도를 최대로 두어 균일한 확률 분포를 구성
최대 엔트로피 원리 • 제약조건을 만족하는 확률 분포들 중 엔트로피가 최대가 되도록 모델을 구성 • 알려진 또는 사용하고자 하는 정보에 대해 확실히 지켜주고, 고려하지 않은 경우나 모르는 경우에 대해서는 동등하게 가중치를 줌으로써 특정 부분에 치우치지 않는 분포를 구한다 Ref. [1]
NN NNS NNP NNPS VBZ VBD 3 5 11 13 3 1 최대 엔트로피 예 • 이벤트 공간 • 경험적 데이터 • 엔트로피를 최대로 하는 확률 분포 • 제약조건: E[NN, NNS, NNP, NNPS, VBZ, VBD]=1 Ref. [3]
NN NNS NNP NNPS VBZ VBD 8/36 4/36 4/36 8/36 8/36 12/36 12/36 8/36 2/36 2/36 2/36 2/36 최대 엔트로피 예 • N*이 V*보다 더 빈번하게 발생, 이를 자질 함수로 추가 • 고유명사가 보통명사보다 더 빈번하게 발생
최대 엔트로피 모델 구성 요소 • 자질 함수 • 정해놓은 조건들을 만족하는지 여부를 확인 • 일반적으로 이진 함수로 정의 • 제약조건 • 기대치를 구할 때 사용하는 정보는 학습문서로 한정 • 파라미터 추정 알고리즘 • 자질 함수의 가중치를 구하는 방법 • GIS, IIS
최대 엔트로피 모델에서 확률 계산 방법 • 자질 함수를 정의 • 제약조건을 정의 • 선택한 알고리즘을 이용해 자질 함수의 가중치 계산 • 가중치를 이용해 각각의 확률 계산 • 여러 확률 값 중 제일 큰 값을 최종확률로 선택
자질 함수 • Trigger 형태로, 정해놓은 제약조건을 만족하였는지 여부를 구분해주는 함수 • 고려되고 있는 문맥에 사용하고자 하는 정보들이 적용가능한지 결정 Ref. [1]
제약조건 Ref. [1]
파라미터 추정 • 정해진 자질 함수를 학습 문서에 적용시켜 얻어낸 확률 정보를 가장 잘 반영하는 p*를 최우추정법(Maximum Likelihood Estimation) 사용하여 구한다 Ref. [1]
IIS (Improved Iterative Scaling) Ref. [1]
GIS (General Iterative Scaling) Ref. [2]
GIS (General Iterative Scaling) Ref. [2]
Conclusions • Conditional random fields offer a unique combination of properties: • discriminatively trained models for sequence segmentation and labeling • combination of arbitrary and overlapping observation features from both the past and future • efficient training and decoding based on dynamic programming for a simple chain graph • parameter estimation guaranteed to find the global optimum • CRFs main current limitation is the slow convergence of the training algorithm relative to MEMMs, let alone to HMMs, for which training on fully observed data is very efficient.