Download

1 / 40
400 likes | 404 Views
This paper discusses the issues, questions, and design considerations for a network router in the Open Network Lab. It covers topics such as performance targets, SRAM allocation, multicast support, plugin capabilities, buffer management, and usage scenarios.

E N D
An NP-Based Router for the Open Network Lab Jon Turnerwith Patrick Crowley, John DeHart, Brandon Heller, Fred Kuhns, Jing Lu, Mike Wilson, Charlie Wiseman, Dave Zar
Issues and Questions • Dropcounters • What is our performance target? • 5-port Router, full link rates. • How should SRAM banks be allocated? • How many packets should be able to be resident in system at any given time? • How many queues do we need to support? • Etc. • How will lookups be structured? • One operation across multiple DBs vs. multiple operations each on one DB • Will results be stored in Associated Data SRAM or in one of our SRAM banks? • Can we use SRAM Bank0 and still get the throughput we want? • Multicast: • Are we defining how an ONL user should implement multicast? • Or are we just trying to provide some mechanisms to allow ONL users to experiment with multicast? • Do we need to allow a Unicast lookup with one copy going out and one copy going to a plugin? • If so, this would use the NH_MAC field and the copy vector field • Plugins: • Can they send pkts directly to the QM instead of always going back through Parse/Lookup/Copy? • Use of NN rings between Plugins to do plugin chaining • Plugins should be able to write to Stats module ring also to utilize stats counters as they want. • Continued on next slide…
Issues and Questions • XScale: • Can it send pkts directly to the QM instead of always going through Parse/Lookup/Copy path? • ARP request and reply? • What else will it do besides handling ARP? • Do we need to guarantee in-order delivery of packets for a flow that triggers an ARP operation? • Re-injected packet may be behind a recently arrived packet for same flow. • What is the format of our Buffer Descriptor: • Add Reference Count (4 bits) • Add MAC DAddr (48 bits) • Does the Packet Size or Offset ever change once written? • Plugins: Can they change the packet? • Other? • How will we write L2 Headers for multicast packets? • If we are going to do this for multicast, we will do it for all packets, right? • Copy writes MAC DAddr into Buffer descriptor • HF reads MAC DAddr from Buffer descriptor • HF writes full L2 Header into scratch ring data for Tx • Tx takes L2 Header data (14 Bytes) from scratch ring and writes it to TBUF • TX initiates transfer of rest of packet from DRAM to TBUF • Continued on next slide…
Issues and Questions • How will we manage the Free list? • Support for Multicast (ref count in buf desc) makes reclaiming buffers a little trickier. • Scratch ring to Separate ME • Modify dl_buf_drop() • Performance assumptions of blocks that do drops may have to be changed if we add an SRAM operation to a drop • Note: test_and_decr SRAM atomic operation returns pre-modified value • Usage Scenarios: • It would be good to document some typical ONL usage examples. • This might just be extracting some stuff from existing ONL documentation and class projects. • Ken? • It might also be good to document a JST dream sequence for an ONL experiment • Oh my, what I have done now… • Do we need to worry about balancing MEs across the two clusters? • QM and Lookup are probably heaviest SRAM users • Rx and Tx are probably heaviest DRAM users. • Plugins need to be in neighboring MEs • QM and HF need to be in neighboring MEs
Performance • What is our performance target? • To hit 5 Gb rate: • Minimum Ethernet frame: 76B • 64B frame + 12B InterFrame Spacing • 5 Gb/sec * 1B/8b * packet/76B = 8.22 Mpkt/sec • IXP ME processing: • 1.4Ghz clock rate • 1.4Gcycle/sec * 1 sec/ 8.22 Mp = 170.3 cycles per packet • compute budget: (MEs*170) • 1 ME: 170 cycles • 2 ME: 340 cycles • 3 ME: 510 cycles • 4 ME: 680 cycles • latency budget: (threads*170) • 1 ME: 8 threads: 1360 cycles • 2 ME: 16 threads: 2720 cycles • 3 ME: 24 threads: 4080 cycles • 4 ME: 32 threads: 5440 cycles
ONL NP Router (Jon’s Original) xScale xScale add largeSRAM ring TCAM SRAM HdrFmt (1 ME) Rx (2 ME) Parse, Lookup, Copy (3 MEs) Mux (1 ME) QueueManager (1 ME) Tx (2 ME) largeSRAM ring Stats (1 ME) • Each output has common set of QiDs • Multicast copies use same QiD for all outputs • QiD ignored for plugin copies Plugin Plugin Plugin Plugin Plugin SRAM xScale largeSRAM ring
Design Configuration • Add NN rings between Plugins for chaining • Add Plugin write to QM Scratch Ring • Tx is only 1ME • Add Freelist Mgr ME
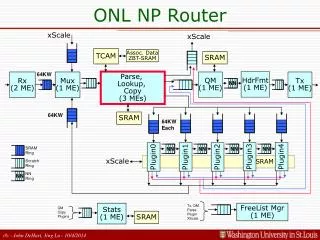
Tx, QM Parse Plugin XScale FreeList Mgr (1 ME) Stats (1 ME) QM Copy Plugins SRAM ONL NP Router xScale xScale TCAM Assoc. Data ZBT-SRAM SRAM HdrFmt (1 ME) Parse, Lookup, Copy (3 MEs) Rx (2 ME) Mux (1 ME) QM (1 ME) Tx (1 ME) NN SRAM SRAM Ring NN NN NN NN Plugin4 Plugin5 Plugin1 Plugin2 Plugin3 SRAM xScale Scratch Ring NN Ring NN
ONL Buffer Descriptor Buffer_Next (32b) LW0 Buffer_Size (16b) Offset (16b) LW1 Packet_Size (16b) Free_list 0000 (4b) Reserved (12b) LW2 MAC DAddr_47_32 (16b) Stats Index (16b) LW3 MAC DAddr_31_00 (32b) LW4 Reserved (28b) Ref_Cnt (4b) LW5 Reserved (32b) LW6 Packet_Next (32b) LW7 Written by Freelist Mgr Written by Rx Written by Copy Written by QM
MR Buffer Descriptor Buffer_Next (32b) LW0 Buffer_Size (16b) Offset (16b) LW1 Packet_Size (16b) Free_list 0000 (4b) Reserved (4b) Reserved (8b) LW2 Reserved (16b) Stats Index (16b) LW3 Reserved (16b) Reserved (8b) Reserved (4b) Reserved (4b) LW4 Reserved (32b) Reserved (4b) Reserved (4b) LW5 Reserved (16b) Reserved (16b) LW6 Packet_Next (32b) LW7
Intel Buffer Descriptor Buffer_Next (32b) LW0 Buffer_Size (16b) Offset (16b) LW1 Packet_Size (16b) Free_list (4b) Rx_stat (4b) Hdr_Type (8b) LW2 Input_Port (16b) Output_Port (16b) LW3 Next_Hop_ID (16b) Fabric_Port (8b) Reserved (4b) NHID type (4b) LW4 FlowID (32b) ColorID (4b) Reserved (4b) LW5 Class_ID (16b) Reserved (16b) LW6 Packet_Next (32b) LW7
SRAM Usage • What will be using SRAM? • Buffer descriptors • Current MR supports 229,376 buffers • 32 Bytes per SRAM buffer descriptor • 7 MBytes • Queue Descriptors • Current MR supports 65536 queues • 16 Bytes per Queue Descriptor • 1 MByte • Queue Parameters • 16 Bytes per Queue Params (actually only 12 used in SRAM) • 1 MByte • QM Scheduling structure: • Current MR supports 13109 batch buffers per QM ME • 44 Bytes per batch buffer • 576796 Bytes • QM Port Rates • 4 Bytes per port • Plugin “scratch” memory • How much per plugin? • Large inter-block rings • Rx Mux • Plugins • Plugins • Stats/Counters • Currently 64K sets, 16 bytes per set: 1 MByte • Lookup Results
SRAM Bank Allocation • SRAM Banks: • Bank0: • 4 MB • Same interface/bus as TCAM • Bank1-3 • 8 MB each • Criteria for how SRAM banks should be allocated? • Size: • SRAM Bandwidth: • How many SRAM accesses per packet are needed for the various SRAM uses? • QM needs buffer desc and queue desc in same bank
SRAM Accesses Per Packet • To support 8.22 M pkts/sec we can have 24 Reads and 24 Writes per pkt (200M/8.22M) • Rx: • SRAM Dequeue (1 Word) • To retrieve a buffer descriptor from free list • Write buffer desc (2 Words) • Parse • Lookup • TCAM Operations • Reading Results • Copy • Write buffer desc (3 Words) • Ref_cnt • MAC DAddr • Stats Index • Pre-Q stats increments • Read: 2 Words • Write: 2 Words • HF • Should not need to read or write any of the buffer descriptor • Tx • Read buffer desc (4 Words) • Freelist Mgr: • SRAM Enqueue – Write 1 Word • To return buffer descriptor to free list.
QM SRAM Accesses Per Packet • QM (Worst case analysis) • Enqueue (assume queue is idle and not loaded in Q-Array) • Write Q-Desc (4 Words) • Eviction of Least Recently Used Queue • Write Q-Params ? • When we evict a Q do we need to write its params back? • The Q-Length is the only thing that the QM is changing. • Looks like it writes it back ever time it enqueues or dequeues • AND it writes it back when it evcicts (we can probably remove the one when it evicts) • Read Q-Desc (4 Words) • Read Q-Params (3 Words) • Q-Length, Threshold, Quantum • Write Q-Length (1 Word) • SRAM Enqueue -- Write (1 Word) • Scheduling structure accesses? • They are done once every 5 pkts (when running full rate) • Dequeue (assume queue is not loaded in Q-Array) • Write Q-Desc (4 Words) • Write Q-Params ? • See notes in enqueue section • Read Q-Desc (4 Words) • Read Q-Params (3 Words) • Write Q-Length (1 Word) • SRAM Dequeue -- Read (1 Word) • Scheduling structure accesses? • They are done once every 5 pkts (when running full rate) • Post-Q stats increments • 2 Reads • 2 Writes
QM SRAM Accesses Per Packet • QM (Worst case analysis) • Total Per Pkt accesses: • Queue Descriptors and Buffer Enq/Deq: • Write: 9 Words • Read: 9 Words • Queue Params: • Write: 2 Words • Read: 6 Words • Scheduling Structure Accesses Per Iteration (batch of 5 packets): • Advance Head: Read 11 Words • Write Tail: Write 11 Words • Update Freelist • Read 2 Words • OR • Write 5 Words
Proposed SRAM Bank Allocation • SRAM Bank 0: • TCAM • Lookup Results • SRAM Bank 1 (2.5MB/8MB): • QM Queue Params (1MB) • QM Scheduling Struct (0.5 MB) • QM Port Rates (20B) • Large Inter-Block Rings (1MB) • SRAM Rings are of sizes (in Words): 0.5K, 1K, 2K, 4K, 8K, 16K, 32K, 64K • Rx Mux (2 Words per pkt): 32KW (16K pkts): 128KB • Plugin (3 Words per pkt): 32KW each (10K Pkts each): 640KB • Plugin (3 Words per pkt): 64KW (20K Pkts): 256KB • SRAM Bank 2 (8MB/8MB): • Buffer Descriptors (7MB) • Queue Descriptors (1MB) • SRAM Bank 3 (6MB/8MB): • Stats Counters (1MB) • Plugin “scratch” memory (5MB, 1MB per plugin)
Lookups • How will lookups be structured? • Three Databases: • Route Lookup: Containing Unicast and Multicast Entries • Unicast: • Port: Can be wildcarded • Longest Prefix Match on DAddr • Routes should be shorted in the DB with longest prefixes first. • Multicast • Port: Can be wildcarded? • Exact Match on DAddr • Longest Prefix Match on SAddr • Routes should be sorted in the DB with longest prefixes first. • Primary Filter • Filters should be sorted in the DB with higher priority filters first • Auxiliary Filter • Filters should be sorted in the DB with higher priority filters first • Will results be stored in Associated Data SRAM or in one of our external SRAM banks? • Can we use SRAM Bank0 and still get the throughput we want? • Priority between Primary Filter and Route Lookup • A priority will be stored with each Primary Filter • A priority will be assigned to RLs (all routes have same priority) • PF priority and RL priority compared after result is retrieved. • One of them will be selected based on this priority comparison. • Auxiliary Filters: • If matched, cause a copy of packet to be sent out according to the Aux Filter’s result.
TCAM Operations for Lookups • Five TCAM Operations of interest: • Lookup (Direct) • 1 DB, 1 Result • Multi-Hit Lookup (MHL) (Direct) • 1 DB, <= 8 Results • Simultaneous Multi-Database Lookup (SMDL) (Direct) • 2 DB, 1 Result Each • DBs must be consecutive! • Care must be given when assigning segments to DBs that use this operation. There must be a clean separation of even and odd DBs and segments. • Multi-Database Lookup (MDL) (Indirect) • <= 8 DB, 1 Result Each • Simultaneous Multi-Database Lookup (SMDL) (Indirect) • 2 DB, 1 Result Each • Functionally same as Direct version but key presentation and DB selection are different. • DBs need not be consecutive. • Care must be given when assigning segments to DBs that use this operation. There must be a clean separation of even and odd DBs and segments.
Lookups • Route Lookup: • Key (68b) • Port/Plugin (4b) • Can be a wildcard for Unicast. • Probably can’t be a wildcard for Multicast • DAddr (32b) • Prefixed for Unicast • Exact Match for Multicast • SAddr (32b) • Unicast entries always have this and its mask 0 • Prefixed for Multicast • Result (72b) • Port/Plugin (4b) • One of 5 ports or 5 plugins. • QID (17b) • NH_IP/NH_MAC/CopyVector (48b) • At most one of NH_IP, NH_MAC or CopyVector should be valid • Valid Bits (3b) • At most one of the following three bits should be set • MCast Valid (1b) • NH_IP_Valid (1b) • NH_MAC_Valid (1b)
Lookups • Filter Lookup • Key (136b) • Port/Plugin (4b) • Can be a wildcard for Unicast. • Probably can’t be a wildcard for Multicast • DAddr (32b) • SAddr (32b) • Protocol (8b) • DPort (16b) • Sport (16b) • TCP Flags (12b) • Exception Bits (16b) • Allow for directing of packets based on defined exceptions • Result (84b) • Port/Plugin (4b) • NH IP(32b)/MAC(48b)/CopyVector(10b) (48b) • At most one of NH_IP, NH_MAC or CopyVector should be valid • QID (17b) • LD (1b): Send to XScale • Drop (1b): Drop pkt • Valid Bits (3b) • At most one of the following three bits should be set • NH IP Valid (1b) • NH MAC Valid (1b) • MCast Valid (1b) • Sampling bits (2b) • For Aux Filters only • Priority (8b) • For Primary Filters only
TCAM Core Lookup Performance Routes Filters • Lookup/Core size of 72 or 144 bits, Freq=200MHz • CAM Core can support 100M searches per second • For 1 Router on each of NPUA and NPUB: • 8.22 MPkt/s per Router • 3 Searches per Pkt (Primary Filter, Aux Filter, Route Lookup) • Total Per Router: 24.66 M Searches per second • TCAM Total: 49.32 M Searches per second • So, the CAM Core can keep up • Now lets look at the LA-1 Interfaces…
TCAM LA-1 Interface Lookup Performance Routes Filters • Lookup/Core size of 144 bits (ignore for now that Route size is smaller) • Each LA-1 interface can support 40M searches per second. • For 1 Router on each of NPUA and NPUB (each NPU uses a separate LA-1 Intf): • 8.22 MPkt/s per Router • Maximum of 3 Searches per Pkt (Primary Filter, Aux Filter, Route Lookup) • Max of 3 assumes they are each done as a separate operation • Total Per Interface: 24.66 M Searches per second • So, the LA-1 Interfaces can keep up • Now lets look at the AD SRAM Results …
TCAM Assoc. Data SRAM Results Performance • 8.22M 72b or 144b lookups • 32b results consumes 1/12 • 64b results consumes 1/6 • 128b results consumes 1/3 Routes Filters • Lookup/Core size of 72 or 144 bits, Freq=200MHz, SRAM Result Size of 128 bits • Associated SRAM can support up to 25M searches per second. • For 1 Router on each of NPUA and NPUB: • 8.22 MPkt/s per Router • 3 Searches per Pkt (Primary Filter, Aux Filter, Route Lookup) • Total Per Router: 24.66 M Searches per second • TCAM Total: 49.32 M Searches per second • So, the Associated Data SRAM can NOT keep up
Lookups: Proposed Design • Use SRAM Bank 0 (4 MB) for all Results • B0 Byte Address Range: 0x000000 – 0x3FFFFF • 22 bits • B0 Word Address Range: 0x000000 – 0x3FFFFC • 20 bits • Two trailing 0’s • Use 32-bit Associated Data SRAM result for Address of actual Result: • Done: 1b • Hit: 1b • MHit: 1b • Priority: 8b • Present for Primary Filters, for RL and Aux Filters should be 0 • SRAM B0 Word Address: 21b • 1 spare bit • Use Multi-Database Lookup (MDL) Indirect for searching all 3 DBs • Order of fields in Key is important. • Each thread will need one TCAM context • Route DB: • Lookup Size: 68b (3 32b words transferred across QDR intf) • Core Size: 72b • AD Result Size: 32b • SRAM B0 Result Size: 72b (3 Words) • Primary DB: • Lookup Size: 136b (5 32b words transferred across QDR intf) • Core Size: 144b • AD Result Size: 32b • SRAM B0 Result Size: 76b (3 Words) • Priority not included in SRAM B0 result because it is in AD result
Lookups: Latency • Three searches in one MDL Indirect Operation • Latencies for operation • QDR xfer time: 6 clock cycles • 1 for MDL Indirect subinstruction • 5 for 144 bit key transferred across QDR Bus • Instruction Fifo: 2 clock cycles • Synchronizer: 3 clock cycles • Execution Latency: search dependent • Re-Synchronizer: 1 clock cycle • Total: 12 clock cycles
Lookups: Latency • 144 bit DB, 32 bits of AD (two of these) • Instruction Latency: 30 • Core blocking delay: 2 • Backend latency: 8 • 72 bit DB, 32 bits of AD • Instruction Latency: 30 • Core blocking delay:2 • Backend latency: 8 • Latency of first search (144 bit DB): • 11 + 30 = 41 clock cycles • Latency of subsequent searchs: • (previous search latency) – (backend latency of previous search) + (core block delay of previous search) + (backend latency of this search) • Latency of second 144 bit search: • 41 – 8 + 2 + 8 = 43 • Latency of third search (72 bit): • 43 – 8 + 2 + 8 = 45 clock cycles • 45 QDR Clock cycles (200 MHz clock) 315 IXP Clock cycles (1400 MHz clock) • This is JUST for the TCAM operation, we also need to read the SRAM: • SRAM Read to retrieve TCAM Results Mailbox (3 words – one per search) • TWO SRAM Reads to then retrieve the full results (3 Words each) from SRAM Bank 0 • but we don’t have to wait for one to complete before issuing the second. • About 150 IXP cycles for an SRAM Read 315 + 150 + 150 = 615 IXP Clock cycles • Lets estimate 650 IXP Clock cycles for issuing, performing and retrieving results for a lookup. (multi-word, two reads, …) • Does not include any lookup block processing
Lookups: SRAM Bandwidth • Analysis is PER LA-1 QDR Interface • That is, each of NPUA and NPUB can do the following. • 16-bit QDR SRAM at 200 MHz • Separate read and write bus • Operations on rising and falling edge of each clock • 32 bits of read AND 32 bits of write per clock tick • QDR Write Bus: • 6 32-bit cycles per instruction • Cycle 0: • Write Address bus contains the TCAM Indirect Instruction • Write Data bus contains the TCAM Indirect MDL Sub-Instruction • Cycles 1-5 • Write Data bus contains the 5 words of the Lookup Key • Write Bus can support 200M/6 = 33.33 M searches/sec • QDR Read Bus: • Retrieval of Results Mailbox: • 3 32-bit cycles per instruction • Retrieval of two full results from QDR SRAM Bank 0: • 6 32-bit cycles per instruction • Total of 9 32-bit cycles per instruction • Read Bus can support 200M/9 = 22.22 M searches/sec • Conclusion: • Plenty of SRAM bandwidth to support TCAM operations AND SRAM Bank 0 accesses to perform all aspects of lookups at over 8.22 M searches/sec.
Objectives for ONL Router • Reproduce approximately same functionality as current hardware router • routes, filters (including sampling filters), stats, plugins • Extensions • multicast, explicit-congestion marking • Use each NPU as separate 5 port router • each responsible for half the external ports • xScale on each NPU implements CP functions • access to control variables, memory-resident statistics • updating of routes, filters • interaction with plugins through shared memory • simple message buffer interface for request/response
Unicast, ARP and Multicast • Each port has Ethernet header with fixed source MAC address – several cases for destination MAC address • Case 1 – unicast packet with destination on attached subnet • requires ARP to map dAdr to MAC address • ARP cache holds mappings – issue ARP request on cache miss • Case 2 – other unicast packets • lookup must provide next-hop IP address • then use ARP to obtain MAC address, as in case 1 • Case 3 – Multicast packet • lookup specifies copy-vector and QiD • destination MAC address formed from IP multicast address • Could avoid ARP in some cases • e.g. point-to-point link • but little advantage, since ARP mechanism required anyway • Do we learn MAC Addresses from received pkts?
Proposed Approach • Lookup does separate route lookup and filter lookup • at most one match for route, up to two for filter (primary, aux) • combine route lookup with ARP cache lookup • xScale adds routes for multi-access subnets, based on ARP • Route lookup • for unicast, stored keys are (rcv port)+(dAdr prefix) • lookup key is (rcv port)+(dAdr) • result includes Port/Plugin, QiD, next-hop IP or MAC address, valid next-hop bit • for multicast, stored keys are (rcv port)+(dAdr)+(sAdr prefix) • lookup key is (rcv port)+(dAdr)+(sAdr) • result includes 10 bit copy vector, QiD • Filter lookup • stored key is IP 5-tuple + TCP flags – arbitrary bit masks allowed • lookup key is IP 5-tuple + flags if applicable • result includes Port/Plugin or copy vector, QiD, next-hop IP or MAC address, valid next-hop bit, primary-aux bit, priority • Destination MAC address passed through QM • via being written in the buffer descriptor? • Do we have 48 bits to spare? • Yes, we actually have 14 free bytes. Enough for a full (non-vlan) ethernet header.
Lookup Processing • On receiving unicast packet, do route & filter lookups • if MAC address returned by route (or higher priority primary filter) is valid, queue the packet and continue • else, pass packet to xScale, marking it as no-MAC • leave it to xScale to generate ARP request, handle reply, insert route and re-inject packet into data path • On receiving multicast packet, do route & filter lookups • take higher priority result from route lookup or primary filter • format MAC multicast address • copy to queues specified by copy vector • if matching auxiliary filter, filter supplies MAC address
ONL NP Router TCAM SRAM HdrFmt (1 ME) Rx (2 ME) Parse, Lookup, Copy (3 MEs) Mux (1 ME) QueueManager (1 ME) Tx (2 ME)
Buf Handle(32b) Eth. Frame Len (16b) Reserved (8b) Port (8b) Buffer Handle(32b) Rsv (4b) Port (4b) QID(20b) Rsv (4b) Frame Length (16b) Stats Index (16b) Port (8) Buf Handle(24b) Frm Length(16b) Frm Offset (16b) V 1 V 1 Rsv (3b) Rsv (3b) Port (4b) Port (4b) Buffer Handle(24b) Buffer Handle(24b) ONL NP Router TCAM SRAM HdrFmt (1 ME) Rx (2 ME) Parse, Lookup, Copy (3 MEs) Mux (1 ME) QueueManager (1 ME) Tx (2 ME)
Buffer Handle(32b) Rsv (4b) Port (4b) QID(20b) Rsv (4b) Frame Length (16b) Stats Index (16b) Port (8) Buf Handle(24b) Frm Length(16b) Frm Offset (16b) ONL NP Router TCAM • Copy • Port: Identifies Source MAC Addr • Write it to buffer descriptor or let HF determine it via port? • Unicast: • Valid MAC: • Write MAC Addr to Buffer descriptor and queue pkt • No Valid MAC: • Prepare pkt to be sent to XScale for ARP processing • Multicast: • Calculate Ethernet multicast Dst MAC Addr • Fct(IP Multicast Dst Addr) • Write Dst MAC Addr to buf desc. • Same for all copies! • For each bit set in copy bit vector: • Queue a packet to port represented by bit in bit vector. • Reference Count in buffer desc. Parse, Lookup, PHF&Copy (3 MEs) • Parse • Do IP Router checks • Extract lookup key • Lookup • Perform lookups – potentially three lookups: • Route Lookup • Primary Filter lookup • Auxiliary Filter lookup
Notes • Need a reference count for multicast. (in buffer descriptor) • How to handle freeing buffer for multicast packet? • Drops can take place in the following blocks: • Parse • QM • Plugin • Tx • Mux Parse • Reclassify bit • For traffic that does not get reclassified after coming from a Plugin or the XScale we need all the data that the QM will need: • QID • Stats Index • Output Port • If a packet matches an Aux filter AND it needs ARP processing, the ARP processing takes precedence and we do not process the Aux filter result. • Does anything other than ARP related traffic go to the XScale? • IP exceptions like expired TTL? • Can users direct traffic for delivery to the XScale and add processing there? • Probably not if we are viewing the XScale as being like our CPs in the NSP implementation.
Notes • Combining Parse/Lookup/Copy • Dispatch loop • Build settings • TCAM mailboxes (there are 128 contexts) • So with 24 threads we can have up to 5 TCAM contexts per thread. • Rewrite Lookup in C • Input and Output on Scratch rings • Configurable priorities on Mux inputs • Xscale, Plugins, Rx • Should we allow plugins to write directly to QM input scratch ring for packets that do not need reclassification? • If we allow this is there any reason for a plugin to send a packet back through Parse/Lookup/Copy if it wants it to NOT be reclassified? • We can give Plugins the capability to use NN rings between themselves to chain plugins.
ONL NP Router xScale xScale add configurable per port delay (up to 150 ms total delay) add largeSRAM ring TCAM Assoc. Data ZBT-SRAM SRAM HdrFmt (1 ME) Rx (2 ME) Parse, Lookup, Copy (4 MEs) Mux (1 ME) QueueManager (1 ME) Tx (1 ME) largeSRAM ring Stats (1 ME) • Each output has common set of QiDs • Multicast copies use same QiD for all outputs • QiD ignored for plugin copies Plugin Plugin Plugin Plugin Plugin SRAM xScale Plugin write access to QM Scratch Ring largeSRAM ring
Plugin4 Plugin5 Plugin2 Plugin3 ONL NP Router xScale xScale TCAM SRAM HdrFmt (1 ME) Rx (2 ME) Parse, Lookup, Copy (4 MEs) Mux (1 ME) QueueManager (1 ME) Tx (1 ME) Stats (1 ME) • Each output has common set of QiDs • Multicast copies use same QiD for all outputs • QiD ignored for plugin copies NN NN NN NN Plugin1 SRAM xScale