Download

1 / 16
160 likes | 269 Views
Learning the Structure of Related Tasks. A. Niculescu-Mizil, R. Caruana. Presented by Lihan He Machine Learning Reading Group Duke University 02/03/2006. Outline. Introduction Learning single Bayes networks from data Learning from related tasks Experimental results Conclusions. x 1.

E N D
Learning the Structure of Related Tasks A. Niculescu-Mizil, R. Caruana Presented by Lihan He Machine Learning Reading Group Duke University 02/03/2006
Outline • Introduction • Learning single Bayes networks from data • Learning from related tasks • Experimental results • Conclusions
x1 x2 x3 x4 Introduction Graphical model: Node represents random variables; edge represents dependency. Undirected graphical model: Markov network Directed graphical model: Bayesian network B={G,θ} Causal relationships between nodes; Directed acyclic graph (DAG) : No directed cycles allowed;
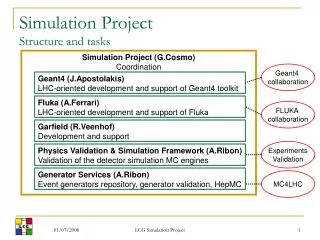
Introduction Goal: simultaneously learn Bayes Net structures for multiple tasks. Different tasks are related; Structures might be similar, but not identical. Example: gene expression data. 1) Learning one single structure from data. 2) Generalizing to multiple task learning by setting joint prior of structures.
Single Bayesian network learning from data Bayes Network B={G, θ}, including a set of n random variables X={X1, X2,…, Xn} Joint probability P(X) can be factorized by Given dataset D={x1, x2, …, xm}, where xi = (x1,x2,…,xn), we can learn structure G and parameter θ from the dataset D.
Single Bayesian network learning from data Model selection: find the highest P(G|D) for all possible G Searching for all possible G is impossible: • n=4, there are 543 possible DAGs • n=10, there are O(1018) possible DAGs Question: How to search the best structure in the huge amount of possible DAGs?
Single Bayesian network learning from data Algorithm: 1) Randomly generate an initial DAG, evaluate its score; 2) Evaluate the scores of all the neighbors of current DAG; 3) while {some neighbors have higher scores than current DAG} move to the neighbor that has the highest score Evaluate the scores of all the neighbors of the new DAG; end 4) Repeat (1) - (3) a number of times starting from different DAG every time.
x1 x2 x3 x1 x1 x1 x4 x2 x2 x2 x3 x3 x3 x1 x4 x4 x4 x2 x3 x4 Single Bayesian network learning from data Neighbors of a structure G: the set of all the DAGs that can be obtained by adding, removing or reversing an edge in G • Must satisfy acyclic constraint
Learning from related task Given iid dataset D1, D2, …, Dk, Simultaneously learn the structure B1={G1, θ1} ,B2={G2, θ2},…,Bk={Gk, θk} Structures (G1,G2,…,Gk) – similar, but not identical
Learning from related task One more assumption: the parameters of different networks are independent: Not true, but make structure learning more efficient. Since we focus on structure learning, not parameter learning, this is acceptable.
Learning from related task Prior: • If structures are not related: G1,…,Gk are independent a priori Structures are learned independently for each task. • If structures are identical, Learning the same structure: Learning the single structure under the restriction that TSK is always the parent of all the other nodes. Common structure: remove node TSK and all the edges connected to it.
Learning from related task Prior: • Between independent and identical: Penalize each edge (Xi, Xj) that is different in two DAGs δ=0: independent δ=1: identical 0<δ<1 For the k task prior
Learning from related task Model selection: find the highest P(G1,…,Gk|D1,…Dk) • Same idea as single task structure learning. • Question: what is a neighbor of (G1,…,Gk) ? Def 1: Size of neighbors: O(n2k) Def 2: Def1 + one more constraint: All the changes of edges happen between the same two nodes for all DAGs in (G1,…,Gk) Size of neighbors: O(n23k)
Learning from related task Acceleration: At each iteration, algorithm must find best score from a set of neighbors Not necessary search all the elements in The first i tasks are specified and the rest k-i tasks are not specified. where is the upper bound of the neighbor subset
Results • Original network, delete edges with probability Pdel,create 5 tasks. • 1000 data points. • 10 trials • Compute KL-divergence and editing distance between learned structure and true structure. KL-divergence Editing distance