Download
1 / 27
270 likes | 384 Views
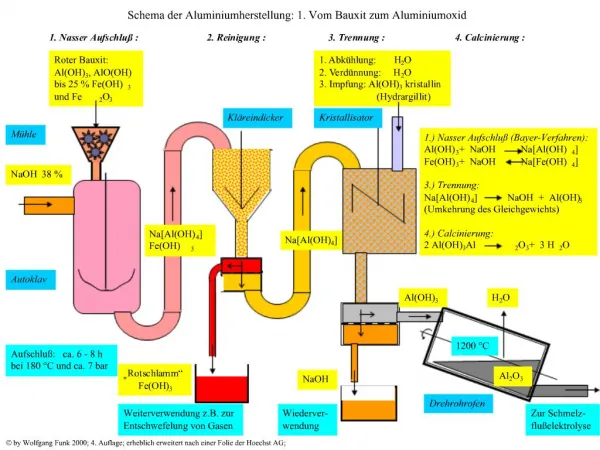
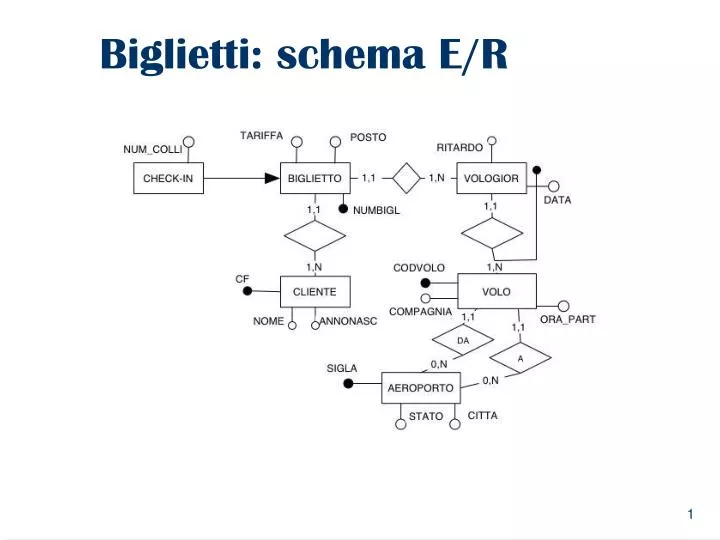
Biglietti: schema E/R. Biglietti: albero degli attributi. Biglietti: albero degli attributi. Dimensioni, Misure e Schema. Dimensioni = {CodVolo, Data, Check-in,AnnoNascitaCliente} Tra le dimensioni non ho tutti gli attributi chiave di BIGLIETTO. GLOSSARIO delle MISURE

E N D
Dimensioni, Misure e Schema • Dimensioni ={CodVolo, Data, Check-in,AnnoNascitaCliente} • Tra le dimensioni non ho tutti gli attributi chiave di BIGLIETTO GLOSSARIO delle MISURE NUM. BIGLIETTI = COUNT(*) INCASSO = SUM(BIGLIETTO.tariffa) NUM. COLLI = SUM(BIGLIETTO.NumeroColli)
Modifica dello schema di fatto • Si aggiunge allo schema di fatto la dipendenza CITTA STATO • Tale dipendenza non era inizialmente espressa nello schema E/R e si può rilevare ed aggiungere allo schema E/R durante la fase di ricognizione dei dati. • Oppure può essere rilevata ed aggiunta dal progettista durante la costruzione dell’albero degli attributi (aggiunta di una dipendenza funzionale). • Oppure può essere rilevata durante l’analisi del carico di lavoro, ad esempio, analizzando la possibilità di fare una interrogazione del tipo “per ogni stato, confrontare gli incassi delle sue città”.
Progettazione logica • Riportando le dimensioni degeneri nella fact table e traducendo la gerarchia condivisa in una sola dimension table, si ottiene questo star schema : • Se per la gerarchia condivisa si effettua uno snowflake sul primo attributo condiviso (la SIGLA) si ottiene questo schema :
Alimentazione del Data Mart • Si considera il seguente schema relazionale del DB operazionale DB_BIGLIETTI • Si considera solo l’estrazione statica che viene effettuata quando il DM deve essere popolato per la prima volta e consiste concettualmente in una fotografia dei dati operazionali. l’alimentazione a partire da zero
Alimentazione del Data Mart • Per semplificare il processo di alimentazione, consideriamo dapprima come schema del Data Mart DM_BIGLIETTI il secondo schema di pagina 6, ma senza l’introduzione di chiavi surrogate (infatti le chiavi surrogate devono essere create e gestite durante l’alimentazione), ovvero si utilizzano le chiavi del DB operazionale DB_BIGLIETTI: • Nel seguito vengono dapprima individuate le espressioni SQL utili ad alimentare il DM, poi tali espressioni verranno utilizzate per creare un pacchetto DTS • La generazione delle dimension table VOLO e AEROPORTO è semplice, in quanto corrisponde a copiare le istanze delle rispettive relazioni nel DB_BIGLIETTI. Siccome VOLO si riferisce tramite FK ad AEROPORTO occorre copiare prima AEROPORTO.
Alimentazione del Data Mart • Essendo la fact table BIGLIETTI con granularità temporale, le sue istanze (gli eventi primari) verranno determinate tramite un raggruppamento sulle dimensioni • Per alimentare la fact table occorre effettuare delle interrogazioni sul DB operazionale (DB_BIGLIETTI) e riportarne il risultato nel DM (DM_BIGLIETTI). Normalmente una query SQL può essere riferita solo ad un DataBase, allora procediamo in questo modo • Nel DB operazionale si crea la query che calcola le istanze della fact table e si memorizza tale query in una vista (VIEW_BIGLIETTI) • Si copia il contenuto della vista VIEW_BIGLIETTI nella table fact BIGLIETTI del DM • Per semplicità, effettuiamo prima il calcolo senza la dimensione CHECK_IN, che ricordiamo essere una dimensione con valore boolean (1 = biglietto con check_in, 0 = bigletto senza check_in).
Alimentazione del Data Mart • La view VIEW_BIGLIETTI deve contenere il join tra BIGLIETTI, CHECK_IN (per prendere NUMCOLLI) e CLIENTE (per prendere ANNONASC) ed il raggruppamento su DATA, CODVOLO, ANNONASC • Conviene fare il join graficamente (vedi figura) quindi salvare la view, riaprirla e scrivere a mano il raggruppamento
Alimentazione del Data Mart • Si deve considerare se è sufficiente fare l’INNER JOIN oppure si deve fare un OUTER JOIN … • Tra BIGLIETTO e CLIENTE è sufficiente l’INNER JOIN in quanto tutti i biglietti hanno un cliente (questo si vede dall’E/R ma si deve verificare in pratica sul relazionale, controllando che il campo CLIENTE in BIGLIETTI sia not null ) • Tra BIGLIETTO e CHECK_IN è necessario fare un outer join per includere anche i biglietti che non hanno corrispondente in CHECK_IN …
Alimentazione del Data Mart • Aprendo la view, aggiungo il GROUP BY e le misure: • La somma di un insieme di valori con almeno un NULL è teoricamente NULL: per avere 0 invece che NULL mettiamo allora SUM(ISNULL(NUMCOLLI,0)). In SQL SERVER il NULL nella somma è considerato per default 0, quindi si può non inserire ISNULL.
Alimentazione del Data Mart • Cosa avviene se un valore di un attributo di ragruppamento è NULL? • Supponiamo che ANNONASC possa essere NULL, sia a causa di BIGLIETTI senza un CLIENTE specificato, sia perchè il cliente ha un ANNONASC nullo. • In questi casi conviene codificare il valore NULL con un opportuno valore, ad esempio 0; In questo modo tale valore non crea problemi quando utilizzato come valore di chiave. Nella view si sostituisce dbo.CLIENTE.ANNONASC con ISNULL(dbo.CLIENTE.ANNONASC, 0) AS ANNONASC. • A questo punto la creazione della view (VIEW1) per alimentare la fact table senza la dimensione CHECK_IN è terminata. Nel seguito discuteremo come introdurre tale dimensione
Alimentazione del Data Mart • La dimensione CHECK_IN è particolare in quanto non corrisponde ad un attributo dello schema del DB operazionale, ma deve essere calcolato: 1 = biglietto con check_in, 0 = bigletto senza check_in. • In base alla discussione già fatta sul left join, possiamo calcolare tale valore effettuando il left join; questo calcolo, riportato nelle slide seguenti, risulta essere complesso, in quanto richiede la definizione di più viste. • Una soluzione più semplice è quella di aggiungere l’attributo alla tabella BIGLIETTO e di calcolarlo tramite UPDATE sulla tabella. In pratica tale soluzione corrisponde alla traduzione del subset CHECK_IN con il “collasso verso l’alto”, dove CHECK_IN è l’attributo selettore UPDATE BIGLIETTO SET CHECK_IN = 0 WHERE NUMBIGLIETTO NOT IN (SELECT NUMBIGLIETTO FROM [CHECK-IN]) UPDATE BIGLIETTO SET CHECK_IN = 1 WHERE NUMBIGLIETTO IN (SELECT NUMBIGLIETTO FROM [CHECK-IN])
Alimentazione del Data Mart • Avendo a disposizione l’attributo CHECK_IN, l’alimentazione della fact table con tale dimensione è molto semplice, basta aggiungerlo agli attributi di raggruppamento • La vista (VIEW_BIGLIETTI) per alimentare la fact table è quindi: • Ora il contenuto della vista può essere copiato nella table fact BIGLIETTI del DM. • Conclusioni • Normalmente, il calcolo è un raggruppamento sulle dimensioni • Considerazioni sui join tra tabelle: LEFT JOIN • Considerazioni sui valori nulli: ISNULL
Alimentazione del Data Mart: creazione di pacchetti DTS • Si svuota il contenuto del DM: è utile per testare le procedure di estrazione statica • Si copiano le dimensional table: l’unico vincolo da rispettare è quello dell’integrità referenziale: quando si copia la tabella A, devono essere già state copiate tutte le tabelle alle quali A si riferisce tramite una FK • Si definisce un pacchetto DTS per ogni passo. Siccome in ogni passo si devono semplicemente copiare delle tabelle è conveniente (è più semplice) creare tale pacchetto tramite “Importa Dati” • In uno star schema si possono copiare tutte le dimension table in un solo passo • Si copia il contenuto della vista nella fact table • Ai passi generali riportati si possono aggiungere altre operazioni che dipendono dal contesto; ad esempio le istruzioni di update di pagina 14. • Dopo aver creato e provato i pacchetti (package) per i singoli passi, si puo creare un unico package che li include tutti, eseguendoli nell’ordine stabilito
Alimentazione del Data Mart • Calcolo dell’attributo CHECK_IN utilizzando le viste • In base alla discussione già fatta sul left join, possiamo calcolare tale valore effettuando il left join :
Alimentazione del Data Mart • L’attributo CHECK_IN si ricava da [CHECK-IN].NUMBIGLIETTO con un semplice if (usiamo il case di SQL-SERVER): CASE WHEN (dbo.[CHECK-IN].NUMBIGLIETTO IS NULL) THEN 0 ELSE 1 ENDAS CHECK_IN • SQL-SERVER non consente di raggruppare su un attributo calcolato tramite CASE • Si crea una prima vista con l’attributo calcolato tramite il case • Si raggruppa su tale vista
CUBO • Dimensione ArrivaA : non si può usare (come in figura) la stessa tabella AEROPORTO • Dimensione ParteDa : quando viene salvato il cubo, vengono contati i membri di ciascun livello; se il numero di CodVolo risulta inferiore a quello del livello padre Sigla (messaggio in basso) occorre rifare il conteggio in modo da contare le sigle effettivamente presenti
CUBO : gerarchia condivisa • Dimensione ArrivaA : non si può usare (come in figura) la stessa tabella AEROPORTO definendo un altro join tra VOLO e AEROPORTO sulla base dell’attributo A : è come se venissero considerati solo i voli che partono ed arrivano allo stesso aeroporto (la figura piccola riporta la visualizzazione)!
CUBO : gerarchia condivisa • Dimensione ArrivaA : si deve inserire una nuova “copia” di AEROPORTO • AEROPORTO usato in ParteDA si rinomina in AeroportoDa (cambia alias) • Si inserisce ancora la tabella AEROPORTO • Si procede con la definizione di ArrivaA • Un altro esempio di cubo con gerarchia condivisa è in http://dbgroup.unimo.it/SIA/EsempioTelefonate/Telefonate.html • Completare il cubo definendo le altre dimensioni e le misure. Introdurre la misura CostoMedioBiglietto (CMB), calcolata come INCASSO/NUM_BIG. Implementazione in Analysis Services • Si definisce la misura derivata CMB_Base • Si definisce la misura di supporto Conteggio, aggregata con COUNT • Si definisce CMB calcolata come CMB_Base/Conteggio
CUBO • Completare il cubo definendo le altre dimensioni e le misure • Introdurre la misura CostoMedioBiglietto (CMB), calcolata come INCASSO/NUM_BIG. Implementazione in Analysis Services • Si definisce la misura derivata CMB_Base • Si definisce la misura di supporto Conteggio, aggregata con COUNT • Si definisce CMB calcolata come CMB_Base/Conteggio • Può essere conveniente, per analizzare i dati, definire vari cubi relativi alla stessa fact table, ciascuno con un sottoinsieme delle misure e/o dimensioni. • Per facilitare la definizione di più cubi, conviene definire le dimensioni come condivise, in modo da definirle una sola volta e riutilizzarle nei vari cubi • In presenza di più cubi è possibile effettuare l’operazione di “drill-across” per analizzare/confrontare i dati di due cubi congiuntamente: nell’Analysis Service questo viene effettuato tramite i CUBI VIRTUALI • D’altra parte, nell’Analysis Service un cubo può essere riferito ad una sola fact table: il cubo virtuale è quindi indispensabile per analizzare/confrontare i dati relativi a due o più fact table
OLAP MANAGER - CUBI VIRTUALI • Primo cubo: con fact table INSEGNAMENTI_CORSI_SSD • Conviene condividere le dimensioni in modo da usarle nel secondo cubo
OLAP MANAGER - CUBI VIRTUALI • Secondo cubo: con fact table INSEGNAMENTI • In pratica si devono definire solo le misure, in quanto si riutilizzano le dimensioni precedenti
OLAP MANAGER - CUBI VIRTUALI • CUBO VIRTUALE: come unione dei due cubi precedenti • Procedura di creazione molto immediata ed intuitiva • L’editor è differente rispetto ai cubi semplici
OLAP MANAGER - CUBI VIRTUALI • Nell’esempio precedente è stato considerato l’unione tra due cubi aventi le stesse dimensioni. • D’altra parte non c’è alcuna limitazione nella definizione di un cubo virtuale: si può definire un cubo virtuale come unione di due cubi con insiemi di dimensioni differenti o, al limite, che non condividono alcuna dimensione: • In corrispondenza di membri di dimensioni differenti, non esisterà alcun evento nel cubo virtuale. Più precisamente • Sia CV un cubo virtuale ottenuto come unione di C1 e C2 • Sia D1 (D2) una dimensione di C1 (C2) non presente in C2 (C1) • Allora le celle non vuote (ovvero gli eventi esistenti) sono solo in corrispondenza di • (D1.All, D2.x), con x membro di D2 • (D1.y, D2.All), con y membro di D1
OLAP MANAGER – Proprietà dei membri e dimensioni virtuali • Gli attributi descrittivi collegati ad attributi dimensionali si può usare “Proprietà membro” • Nell’esempio, un possibile attributo descrittivo è il nome inglese dell’insegnamento. • Una dimensione virtuale è una dimensione rispetto alla quale non vengono calcolati e materializzati dati aggregati • Logicamente, non c’è nessuna differenza tra dimensioni “ordinarie” e dimensioni virtuali • Una dimensione virtuale viene definita rispetto ad una proprietà di un membro di una dimensione “ordinaria”