Download

1 / 13
130 likes | 235 Views
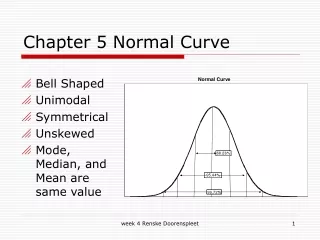
Lecture 9 Chapter 5. Non-Normal Populations. 5.1 Introduction Throughout the course ( in Chapters 2, 3 and 4) we have focussed on data which we can assume comes from the Normal distribution. However, some experiments give results that cannot sensibly be modelled by a Normal distribution.

E N D
5.1 Introduction • Throughout the course ( in Chapters 2, 3 and 4) we have focussed on data which we can assume comes from the Normal distribution. • However, some experiments give results that cannot sensibly be modelled by a Normal distribution. • In some cases this is because the distribution just has a different shape. Other times, the data are of a completely different type, e.g. categories rather than numbers.
5.2 Non-parametric methods We first consider the situation where our data are continuous but may not be Normally distributed, and in fact we do not know what distribution might be appropriate. In these cases, the methods that we have studied so far in this course, t-tests, ANOVA etc. are not appropriate, and must be replaced by tests which do not assume the Normal distribution, or indeed any other distribution.
Methods which do not assume the data come from any distribution are called distribution-free, or non-parametric. Example The speech of two groups of speech-impaired children is assessed following two different programmes of treatment: Group A: Active Speech Therapy Group B: Conversation Sessions
The following data are scores on a scale in which higher values represent greater difficulty in speaking. Group A 1.7 2.8 1.5 2.2 2.7 1.7 1.8 2.2 1.8 3.2 1.7 2.0 2.2 2.1 Group B 3.4 2.2 3.7 3.1 2.0 2.6 2.8 2.1 Let’s look at histograms…
If we could assume these data to be normally distributed, we could use a two-sample t-test. However, this assumption is difficult to justify here. So, we use the appropriate non-parametric test for comparing two independent samples, which is called the Mann-Whitney test. The details of how to do the calculations for this are not necessary here. We omit them and go straight to the implementation in Minitab using the command: Stat>Nonparametrics>Mann-Whitney... For our data, we get p = 0.0307. This is significant at the 5% level, so we have evidence for a difference in the two treatments. Active speech therapy appears to be more effective than conversation sessions.
5.3 When the Data are counts:a) The Binomial Distribution We now consider a different kind of data altogether. Instead of numbers measured on a continuous scale, we consider situations where our data are counts of different kinds. In this section we consider what happens when we count the successes from a number of trials. The Binomial distribution is used to model the number of successes in a series of nindependent trials, where each trial results in either a ‘success’ or a ‘failure’.
Let’s first see how this works. Example A drug is known to be 80% effective, i.e. the probability that each person with the disease will be cured is 0.8. Suppose four people with the disease are given the drug. What is the probability distribution for the number of people cured?
Notation Let X = number of people cured. Let s denote a success. Let f denote a failure. Consider a typical outcome of the experiment for the four people, e.g. that the first two are cured, and the second two are not. We would write this outcome: s s f f. Since each person is cured (or not cured) independently, we can calculate the probability of this outcome as Pr (s s f f) = Pr(s) x Pr(s) x Pr(f) x Pr(f) = 0.8 x 0.8 x 0.2 x 0.2 = 0.0256.
We could do similar calculations for all of the possible outcomes: Outcome Probability 1. ssss 0.8 x 0.8 x 0.8 x 0.8 = 0.4096 2. sssf etc. 3. ssfs 4. ssff 0.8 x 0.8 x 0.2 x 0.2 = 0.0256 5. sfss etc. 6. sfsf 0.8 x 0.2 x 0.8 x 0.2 = 0.0256 7. sffs 0.8 x 0.2 x 0.2 x 0.8 = 0.0256 8. sfff etc. 9. fsss 10. fssf 0.2 x 0.8 x 0.8 x 0.2 = 0.0256 11. fsfs 0.2 x 0.8 x 0.2 x 0.8 = 0.0256 12. fsff etc. 13. ffss 0.2 x 0.2 x 0.8 x0.8 = 0.0256 14. ffsf etc. 15. fffs 16. ffff 0.2 x 0.2 x 0.2 x 0.2 = 0.0016
Now suppose we want to know the probability that exactly two of the four patients are cured (not necessarily the first two), i.e. Pr (X=2). We can obtain this probability by adding up the probabilities for all of the outcomes in the table for which X=2. There are six of these, i.e. outcomes 4, 6, 7, 10, 11 and 13. Each of these outcomes has probability 0.0256. So: Pr (X = 2) = 6 x 0.0256 = 0.1536.
We can do similar calculations to obtain: Pr (X = 4) = 0.4096 Pr (X = 3) = 0.4096 Pr (X = 1) = 0.0256 Pr (X = 0) = 0.0016 In practice we get Minitab to do the calculations.