Download
1 / 1
10 likes | 140 Views
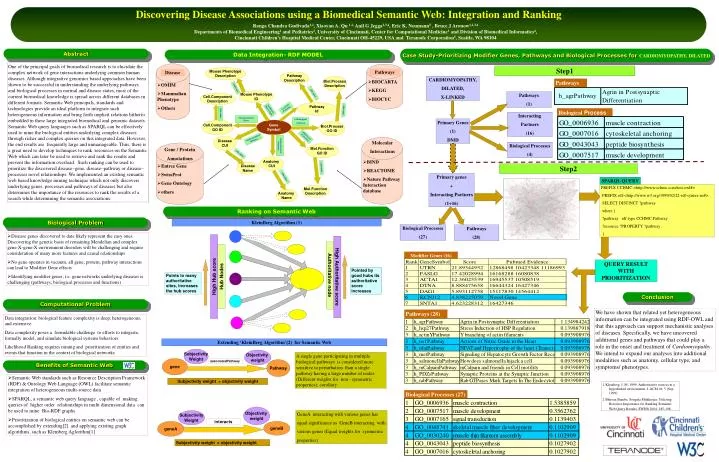
BIOCARTA KEGG BIOCYC. OMIM Mammalian Phenotype Others. Pathways. Disease. Discovering Disease Associations using a Biomedical Semantic Web: Integration and Ranking. Ranga Chandra Gudivada 1,2 , Xiaoyan A. Qu 1,2, Anil G Jegga 2,3,4 , Eric K. Neumann 5 , Bruce J Aronow 1,2,3,4

E N D
BIOCARTA • KEGG • BIOCYC • OMIM • Mammalian Phenotype • Others Pathways Disease Discovering Disease Associations using a Biomedical Semantic Web: Integration and Ranking Ranga Chandra Gudivada1,2, Xiaoyan A. Qu 1,2, Anil G Jegga2,3,4, Eric K. Neumann5 , Bruce J Aronow1,2,3,4 Departments of Biomedical Engineering1 and Pediatrics2, University of Cincinnati, Center for Computational Medicine3 and Division of Biomedical Informatics4, Cincinnati Children’s Hospital Medical Center, Cincinnati OH-45229, USA and Teranode Corporation5, Seattle, WA 98104 Abstract Case Study-Prioritizing Modifier Genes, Pathways and Biological Processes for CARDIOMYOPATHY, DILATED Data Integration- RDF MODEL One of the principal goals of biomedical research is to elucidate the complex network of gene interactions underlying common human diseases. Although integrative genomics based approaches have been shown to be successful in understanding the underlying pathways and biological processes in normal and disease states, most of the current biomedical knowledge is spread across different databases in different formats. Semantic Web principals, standards and technologies provide an ideal platform to integrate such heterogeneous information and bring forth implicit relations hitherto embedded in these large integrated biomedical and genomic datasets. Semantic Web query languages such as SPARQL can be effectively used to mine the biological entities underlying complex diseases through richer and complex queries on this integrated data. However, the end results are frequently large and unmanageable. Thus, there is a great need to develop techniques to rank resources on the Semantic Web which can later be used to retrieve and rank the results and prevent the information overload. Such ranking can be used to prioritize the discovered disease–gene, disease–pathway or disease–processes novel relationships. We implemented an existing semantic web based knowledge mining technique which not only discovers underlying genes, processes and pathways of diseases but also determines the importance of the resources to rank the results of a search while determining the semantic associations. Step1 Mouse Phenotype Description Pathway Description CARDIOMYOPATHY, DILATED, X-LINKED Biol.Process Description Pathways rdfs:label Mouse Phenotype ID rdfs:label Pathways (1) Cell.Component Description Pathway Id occursIn Pathway hasMouse PhenoType rdfs:label Biological Process rdfs:label Interacting Partners (16) hasAssociated Gene inBiological Process Primary Genes (1) DMD Gene Symbol Cell.Component GO ID Biol.Process GO ID inMolecula rFunction hasAssociated Disease Disease CUI • BIND • REACTOME • Nature Pathway Interaction database Molecular Interactions Biological Processes (4) hasAssociated Anatomy • Entrez Gene • SwissProt • Gene Ontology • others Mol.Function GO ID Gene / Protein Annotations rdfs:label Anatomy CUI Disease Name Step2 rdfs:label Primary genes + Interacting Partners (1+16) rdfs:label SPARQL QUERY PREFIX CCHMC:<http://www.cchmc.com/test.owl#> PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#> SELECT DISTINCT ?pathway where { ?pathway rdf:type CCHMC:Pathway . ?resource ?PROPERTY ?pathway . } Mol.Function Description Anatomy Name Ranking on Semantic Web Biological Problem KleinBerg Algorithm (1) Biological Processes (27) Pathways (28) • Disease genes discovered to date likely represent the easy ones. Discovering the genetic basis of remaining Mendelian and complex gene-X-gene-X-environment disorders will be challenging and require consideration of many more features and causal relationships • No gene operates in vacuum, all gene, protein, pathway interactions can lead to Modifier Gene effects • Identifying modifier genes, i.e. gene networks underlying diseases is challenging (pathways, biological processes and functions) Modifier Genes (16) QUERY RESULTWITH PRIORITIZATION Pointed by good hubs its authoritative score increases Authoritative node Points to many authoritative sites, increases the hub scores Hub Nodes High Hub score High Authoritative score Conclusion Computational Problem We have shown that related yet heterogeneous information can be integrated using RDF-OWL and that this approach can support mechanistic analyses of diseases. Specifically, we have uncovered additional genes and pathways that could play a role in the onset and treatment of Cardiomyopathy. We intend to expand our analyses into additional modalities such as anatomy, cellular type, and symptoms/ phenotypes. Pathways (28) Data integration: biological feature complexity is deep, heterogeneous, and extensive. Data complexity poses a formidable challenge to efforts to integrate, formally model, and simulate biological systems behaviors Likelihood Ranking requires mining and prioritization of entities and events that function in the context of biological networks Extending ‘KleinBerg Algorithm’(2) for Semantic Web Subjectivity Weight Objectivity weight A single gene participating in multiple biological pathways is considered more sensitive to perturbation than a single pathway having a large number of nodes (Different weights for non - symmetric properties); corollary : gene associatedPathway Pathway Benefits of Semantic Web • Semantic Web standards such as Resource Description Framework (RDF) & Ontology Web Language (OWL) facilitate semantic integration of heterogeneous multi-source data • SPARQL, a semantic web query language , capable of making queries of higher order relationships in multi dimensional data can be used to mine Bio-RDF graphs • Prioritization of biological entities on semantic web can be accomplished by extending[2] and applying existing graph algorithms, such as Kleinberg Aglorithm[1] Subjectivity weight > objectivity weight 1.Kleinberg, J. M. 1999. Authoritative sources in a hyperlinked environment. J. ACM 46, 5 (Sep. 1999) 2 Bhuvan Bamba, Sougata Mukherjea: Utilizing Resource Importance for Ranking Semantic Web Query Results. SWDB 2004: 185-198 Biological Processes (27) Objectivity weight Subjectivity Weight GeneA interacting with various genes has equal significance as GeneB interacting with various genes (Equal weights for symmetric properties) interacts geneA geneB Subjectivity weight = objectivity weight