Download

1 / 24
240 likes | 413 Views
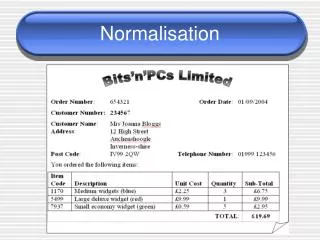
Normalisation. Africamuseum 5 June 2013. What is ‘Normalisation’?. Theoretical: satisfying the requirements of the different ‘Normal Forms’, as spelled out by (mainly) E.F. Codd Practical: make sure data is in your database once and only once Repeated data go to separate table

E N D
Normalisation Africamuseum 5 June 2013
What is ‘Normalisation’? • Theoretical: satisfying the requirements of the different ‘Normal Forms’, as spelled out by (mainly) E.F. Codd • Practical: make sure data is in your database once and only once • Repeated data go to separate table • Relationships between the tables are part of the ‘model’ of the database
Earlier example Species # legs # eyes place Country date Asterias rubens 5 0 Oostende Belgium 12/3/2004 Asterias rubens 5 0 Zeebrugge Belgium 13/3/2005 Asterias rubens 5 0 Zeebrugge Belgium 14/3/2005 Cancer pagurus 10 2 De Panne Belgium 12/3/2004 Cancer pagurus 10 2 Oostende Belgium 12/3/2004 Cancer pagurus 10 2 Zeebrugge Belgium 14/3/2004 Asterias rubens 5 0 Wimereux France 13/3/2005 Asterias rubens 5 0 Wimereux France 14/3/2005 Cancer pagurus 10 2 Wimereux France 12/3/2004
Why normalise • Save space on disk by avoiding repetition • But huge disk space makes this less important • Zipping would replace repeated strings by a code • Avoid ‘modification anomalies’ • Make model intuitive and informative • Make database unbiased with respect to patterns of querying
Modification anomalies • Update anomalies • Potential source of conflicting data • Insertion anomalies • Some relevant data can’t be stored • Deletion anomalies • Some relevant data are lost while deleting other data
Update anomalies If data is present more than once, it’s possible to create conflicting information by updating one version of he data and not the other Species # legs # eyes place Country date Asteriasrubens6 0 Oostende Belgium 12/3/2004 Asteriasrubens 5 0 Zeebrugge Belgium 13/3/2005 Asteriasrubens 5 1ZeebruggeFrance 14/3/2005
Insertion anomalies If two concepts are mixed in one table, we can’t store information on new items of one type, unless we have at the same time information on the other Species # legs # eyes place Country date Asteriasrubens 5 0 Oostende Belgium 12/3/2004 Asteriasrubens 5 0 Zeebrugge Belgium 13/3/2005 Asteriasarenata 5 0 <null> <null> <null>
Deletion anomalies If two concepts are mixed in one table, we loose information on a concept if the last instance of the other concept is deleted Species # legs # eyes place Country date Asteriasrubens 5 0 Oostende Belgium 12/3/2004 Asteriasrubens 5 0 Zeebrugge Belgium 13/3/2005 Asteriasarenata 5 0 Zeebrugge Belgium 13/3/2005
Making model more intuitive A good model should reflect the reality it tries to mirror, including the relationships between the entities. Separate entities in real life (can be abstract) should be modelled separately Species # legs # eyes place Country date Asteriasrubens 5 0 Oostende Belgium 12/3/2004 Asteriasrubens 5 0 Zeebrugge Belgium 13/3/2005 Shared biological biogeographical
… and robust • Entries in a database should be ‘atomic’ • Should not be a combination of several smaller entities such as ‘Oostende, Belgium’ • Contain no qualifiers (such as Asterias cfr rubens; Asterias ?rubens…) • Not be dependent on the value of another field • Not contain repeated values (e.g. several authors for a multi-author publication)
Avoid bias • Asterias rubens • Oostende, Belgium, 12/3 • Zeebrugge, Belgium, 13/3 • Wimereux, France, 13/3 • Asterias arenata • Den Osse, Netherlands, 17/3 • Cancer pagurus • Oostende, Belgium, 12/3 • De Panne, Belgium, 12/3 • Den Osse, Netherlands, 14/5 • Abra alba • Oostende, Belgium, 14/5 A ‘nested list’ is easier to query on the grouping factor of the list. It is easy to find in which countries Asterias rubens occurs; to find out which species occur in say France, we must read our complete database
The formal process The key, The whole key, And nothing but the key… So help me (E.F.) Codd
N1NF (non-1 Normal Form) • Asterias rubens • Oostende, Belgium, 12/3 • Zeebrugge, Belgium, 13/3 • Wimereux, France, 13/3 • Asterias arenata • Den Osse, Netherlands, 17/3 • Cancer pagurus • Oostende, Belgium, 12/3 • De Panne, Belgium, 12/3 • Den Osse, Netherlands, 14/5 • Abra alba • Oostende, Belgium, 14/5
N1NF • Structure of the ‘table’: • drs (species, legs, eyes, place1, country1, date1, place2, country2, date2, place3, country3, date3) • Entries are not atomic, difficult to query • What if we have a fourth distribution record??
1NF Species # legs # eyes place Country date Asterias rubens 5 0 Oostende Belgium 12/3/2004 Asterias rubens 5 0 Zeebrugge Belgium 13/3/2005 Asterias rubens 5 0 Zeebrugge Belgium 14/3/2005 Cancer pagurus 10 2 De Panne Belgium 12/3/2004 Cancer pagurus 10 2 Oostende Belgium 12/3/2004 Cancer pagurus 10 2 Zeebrugge Belgium 14/3/2004 Asterias rubens 5 0 Wimereux France 13/3/2005 Asterias rubens 5 0 Wimereux France 14/3/2005 Cancer pagurus 10 2 Wimereux France 12/3/2004
1NF: the key • A distribution record (a line in our table) is unique when taking into account species, place and date • drs (species, place,date, legs, eyes, country) Table names are usually plural, field (column) names singular. In this type of analysis keys are underlined
2NF: the whole key • Moving repeating groups to separate entities, and looking for a key for that entity: remove entities that are dependent only on part of the compound key • Distribution records (species, place, date) • Species (species, legs, eyes) • Places (place, country)
2NF: foreign keys • The one original table was split in three • Distribution records (drs), species, places • Table drs and species share a field, species, that allow us to find related records • Field species is foreign key in table drs • Same with drs and places • Species and places can be populated from reference tables (CoL; Gazetteer)
3NF: nothing but the key • Moving attributes that are functionally dependent on non-key attribute • Possible structure (in this case same as 2NF) • Distribution records (species, place, date) • Places (place, country) • Species (species, legs, eyes)
Elaborating further: IDs • Key of drs is compound, composed of three fields – better to replace with a ‘synthetic’ key (id – ‘autonumber’ or ‘sequence’) • Keys of ‘places’ and ‘species’ are names with real meaning; anything with meaning in real life can change, so also better to replace with artificial key
Elaborating further: traits • Our database now has information on number of legs and number of eyes. What if we want to start storing colour? Requires rewrite of the database • Alternative: split out data on biological traits in table with ‘property/value’ pairs • Species (id, species, author, parent_id…) • Traits (species_id, trait, value)
Remarks • Sometimes it is better not to normalise completely • Surname & first name as 1 attribute instead of 2 • Calculated fields to speed up queries • Sometimes it is better to denormalise completely • Exchange formats such as Darwin Core
Final remarks • Normalisation is a means, not a goal • Intelligent denormalising is as much an art as normalising!