Download

1 / 62
620 likes | 641 Views
Explore the potential of DNA technology in constructing a pedabit DNA database with associative search capability, enabling massively parallel searches and high-density storage. Learn about DNA operations, biotechnology techniques, associative search methods, and experimental results.

E N D
DNA7 Experimental Construction of Very Large Scale DNA Databases with Associative Search Capability John H. Reif 1, Thomas H. LaBean 1, Michael Pirrung 2, Vipul S. Rana 2, Bo Guo 1, Carl Kingsford 1, and Gene S. Wickham 1Departments of Computer Science1 and Chemistry2Duke University
Goal: Construction of a Pedabit DNA Database with Associative Search Capability • Each data base element encoded by a DNA molecule. • 1015 data base elements stored (with 10-fold redundancy). • 10 milligrams of DNA holds entire database. • 100,000,000 More Storage Density than Conventional Storage Media ! • Massively Parallel Associative Search via DNA annealing. • Parallel I/O to Digital Media can be done via optically addressed DNA arrays.
Organization of Talk: • Introduction to DNA & Overview of Biotechnology • The Associative Search Problem & Relevance • Overview of DNA Search Project • Preliminary Pre-Processing of Image Data Base • Computer Simulation of DNA Search • Design of the DNA Library Coding Sequences • Experimental Construction of the DNA Library • Experiments of Associative Search in DNA Library • High Rate Input/Output via DNA Chips • Current Status DNA Search Project • Future Work
Introduction to DNA & • Overview of Biotechnology
1 Gram of DNA: Extremely compact DNA storage: • contains 2.1 x 1021 DNA bases • can store approximately • 4.2 x 1021 = 4.2 billion trillion bits. Potential Data Storage Capacity of DNA:a factor of 4.2 x 1012 more compact than conventional storage technologies • Actual Experiments: • 1015 data base elements stored (10-fold redundancy) • use only 10 milligrams of DNA: 108 more compact than conventional storage media. • When in solution in in 10 milliliters H2O: 105 more compact than conventional storage media.
The 4 DNA bases form two sets of complementary pairs, known as Watson-Crick complements. Recombinant DNA Operations: • DNA annealing operation: two single stranded DNA sections combine into a doubly stranded DNA if the DNA bases of these sequence are complementary to each other. DNA ligation: • two abutting single stranded DNA sections joined • Primer-extension operation: a DNA strand known as a primer anneals to another DNA strand S which has the complement of that primer as a subsequence; then the use of an enzyme known as polymerase allows for the extension of that primer to form the full sequence complementary to S. • The Polymerase Chain Reaction (PCR): uses repeated primer-extension to amplify only those DNA strands with particular end flanking subsequences defined by the primers.
Biotechnology Techniques Used: • Recombinant DNA operations: • cut & splice DNA in massively parallel fashion • PCR: uses DNA annealing to amplify very small quantities of DNA having a chosen sequence • DNA Annealing Arrays provide: • surfaces for optically addressed • parallel DNA synthesis • optical detection of DNA sequences via florescent labels • input and output of DNA databases to convention digital storage media. • MicroBeads provide: surfaces for parallel DNA synthesis
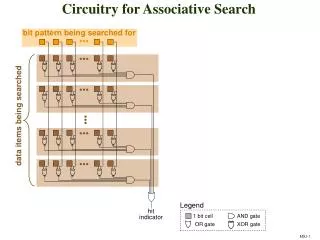
Associative Search • Database: • Ordered list of elements of n-vectors, whose elements range over a finite range. • Each vector of database has a unique identifying index in the database. • Associative Search Query: • Query vector v • Distance bound d. • distance(u,v) = |u1-v1|+ |u2-v2|+… |un-vn| • Find distance d near-matches: • Search the entire database for those vectors of the database that are of distance at most d from the query vector. • Closest match: • Find the index to a vector of the database of smallest distance from the query vector.
Associative Search in Image Database • Preprocess using a procedure A forming an attribute database: • List of low level image attributes for each image or sub-image. • Given an input image I: • Use A to determine its vector A(I) of image attributes. • Associative search in the attribute database provides the closest match to A(I). • Provides an index to that image in the image database whose attributes best match that of the input image I.
DNA Associative Search: Massively parallel associative search in extremely large databases encoded as DNA strands. • [Baum95]: proposed using known recombinant DNA methods for DNA ligation affinity separation. • Use of DNA words for vector elements • Each element of a vector of the database is encoded by a DNA word. • Each n-vector v of database encoded by sequence of n DNA words, followed by DNA word for identifying index to v. • Advantages: • -Ultra-compact DNA storage media • -Supports highly parallel associative searches within media: • Possible methods: • Use known recombinant DNA methods for Detection of Matches: • - PCR for amplification • uses DNA annealing to amplifying the frequency of those DNA strands that have a particular chosen sequence. • -DNA ligation affinity separation. • -Scalable: If < maximum concentration, • # of recombinant DNA operations and volume are independent of database size.
DNA Annealing as a Massively Parallel Associative Search Engine.Major Challenges: • (a) Experimental Construction of a Large Scale DNA Library Data Base • (b) Experimental Testing of Large Scale DNA Associative Search • (c) Refining the Associative Search to Exact Affinity Separation: • The query may not be an exact match or even partial match with any data in the database. • DNA annealing affinity methods: • Work best annealing on complementary sequences. • Do not perform well for associative matching in case of partial matches with scattered mismatches in interior of vectors. • (d) Input and Output (I/O) to Conventional Media: • Goals: error-resiliency and optimal I/O rate for a given error rate. • (e) Extension to Include Boolean Conditionals: • Extend associative search queries to Boolean formula conditionals (with a bounded number of Boolean variables), by combining our methods for DNA associative search with BMC methods for solving the SAT problem. • Example: extended queries executed on: • Natural DNA strands (from blood or other tissues) • Appended with DNA words encoding binary information about each strand (e.g, the social security number of the person whose DNA was sampled, cell type, the date, further medical data, etc.).
Our New Techniques for DNA associative search:J.H. Reif and T. H. LaBean, Computationally Inspired Biotechnologies: Improved DNA Synthesis and Associative Search Using Error-Correcting Codes and Vector-Quantization, Sixth International Meeting on DNA Based Computers (DNA6), DIMACS Series in Discrete Mathematics and Theoretical Computer Science, Leiden, The Netherlands, (June, 2000) ed. A. Condon. Springer-Verlag volume in Lecture Notes in Computer Science, (2000).URL: http://www.cs.duke.edu/~reif/paper/SELFASSEMBLE/selfassemble.pdf We use improved biotechnology techniques based on Error-Correction and VQ Coding. • New Techniques: • The database may initially be in conventional (electronic, magnetic, or optical) media, rather than the form of DNA strands. • Proposed Solution: Apply DNA chip technology improved by Error-Correction and VQ Coding methods for error-correction and compression. • The query may not be an exact match or even partial match with any data in the database, but DNA annealing affinity methods work best for these cases. • Proposed Solution: Apply various VQ Coding methods for refining the associative search to exact matches. • Extend associative search queries in DNA databases to include Boolean formula conditionals (with bounded # of Boolean variables). • Proposed Solution: Combine our methods for DNA associative search with known BMC methods for solving small size SAT problems.
Relevance to Image Databases: • To Execute Associative Search in Digital Image Databases of Huge Size. (Potentially Thousands of Terabytes) Constructing DNA Databases & Executing Associative Search:Preprocess Image Data: - We use image segmentation, wavelet transforms and vector quantization (via C code which we developed)One-time conversion of digital database to DNA database: - Can use parallel optical synthesis on DNA arrays (via known biotechnology) - For experimental purposes, we instead artificially synthesized a huge DNA database. Parallel Associative Search in DNA DataBase: - Executed via PCR amplification and DNA Annealing.
Overview of DNA Search Project Goals of Laboratory Experiments: • Artificially Synthesize random DNA DataBase of huge size • Test Associative Search in the DNA DataBase Use 10-fold redundancy (10 identical DNA per database element). The distinct DNA for any chosen database element is amplified by PCR and detected. Only a total of a 10 milligram of DNA used. Can store 1015 = 1,000 trillion data elements. Can give 108 factor of Storage Density than Conventional Storage Media !
Carl KingsfordGraduate student, Princeton University Software Preprocessing of Image DatabaseInitial Image Preprocessing on Conventional ComputerImage Segmentation: - When Image database was created, the image was broken into tiles. - Tiles are small subimages (typically 8 by 8 or 16 by 16 pixels) that were extracted from the image. - For each pixel in the image: a tile is extracted with its upper-left corner at that pixel. Wavelet Transformation: - Tiles are wavelet transformed and stored in a file on the server (called the DAT file).Vector Quantization(VQ) Transformation: - The index is encoded using the search template. - The resulting tiles are then VQ encoded - The VQ index as well as the position of the tile is encoded into DNA (as specified by the template).(After you click search, the selected tile is wavelet transformed and VQ encoded. )
Vector Quantization (VQ) Coding • Partition vectors of database into clusters of vectors. For each cluster: • The center vector is the average of all the vectors of the cluster. • radius of cluster = maximum distance between any vector of the cluster to center vector. • Cluster index uniquely identifies the cluster. • Well-known algorithms (Jain, Dubes [JD88]) compute clusters: • Minimizing cluster radius • Cluster size parameter m = average number of vectors in each cluster. • Number of clusters is a multiple 1/m of original number of vectors of database. • Used in computer science for compressing data (se.g. speech and images) within bounded error. • Each vector is approximated by the center point of its cluster and coded by the cluster index. • VQ coding induces errors tuned by choice of parameter m. • Data-rate/distortion is asymptotically optimal, • assuming various statistical source models for the data • (memoryless or finite-state stationary processes [Gray90]).
Applying VQ Coding Methods • Applying VQ Coding Methods To Associative Search: Refining the Associative Search to Exact Matches: • DNA annealing affinity methods work best on complementary sequences. • Yet, we need to process an associative match query, even if the query in not an exact match or even partial match with any data in the database. • We use VQ-Coding clustering techniques: • Reduces associative search problem to finding just exact matches via complementary hybridization. • Can be done very effectively by known DNA annealing methods (e.g., PCR). • To Increase DNA Chip I/O: • Use VQ data clustering techniques to determine the clusters. • Only the center points need to be transmitted (at 1/m the cost of transmitting the entire set of the database). • Each vector v of the database is represented by a DNA strand encoding: • Identification tag for v and • Identification tag for center point of cluster containing v.
Applying VQ Coding Methods • Applying VQ Coding Methods To Associative Search: Refining the Associative Search to Exact Matches: • DNA annealing affinity methods work best on complementary sequences. • Yet, we need to process an associative match query, even if the query in not an exact match or even partial match with any data in the database. • We use VQ-Coding clustering techniques: • Reduces associative search problem to finding just exact matches via complementary hybridization. • Can be done very effectively by known DNA annealing methods (e.g., PCR). • To Increase DNA Chip I/O: • Use VQ data clustering techniques to determine the clusters. • Only the center points need to be transmitted (at 1/m the cost of transmitting the entire set of the database). • Each vector v of the database is represented by a DNA strand encoding: • Identification tag for v and • Identification tag for center point of cluster containing v.
Reducing Associative Search with Given Match Distance d to the Problem of Exact Match • For each cluster G of database vectors: • The "possibility vectors" of the cluster are those vectors that are within distance d of the center point of G. • Query vector v will be included among the "possibility vectors" of those clusters whose centers are of distance at most d from v. • Vectors in these clusters are at most distance 2d to v, and they include all database vectors that are at most distance d to the query vector, as required.
Software Simulation of DNA Search • DNA Associative Search Simulation- When you click the "Search" button, the tile is converted into a representation of DNA - BIND is used to simulate hybridation between the search strand and each database strand- The product is a set of DNA strands from the database, called the result set. - Each of the strands in the result set is decoded into the VQ index and the tile position. A white box is drawn on the image at the tile position to indicate that this tile was found. • Carl KingsfordGraduate student, Princeton University
Xavier BerniGraduated Masters Duke University Software Simulation of DNA Annealing - Determine the Search Strand: the DNA strand that represents the tile you are looking for (created from image you selected in the image selection box). This search strand is "dipped" into the DNA database that represents the image.Simulation of DNA Annealing: - between search strand and database strands - Determines Probability Database Strand is Annealed to the Search Strand. - BIND: Software Used for DNA Annealing Simulation Conditions used by BIND simulation:Temperature - the temperature of the solution. Strand concentration - what percentage of the solution is this strand. Salt concentration - what percentage of the solution is salt. MathematicalAnnealing model: represents the binding energies between strands of DNA. Max. Mismatch distance.Input to BIND: the conditions of the solution and two strands Output from BIND: the likelihood that these strands will anneal.
DNA sequences of Hamming distance 1 from ACGT. • 2D Projection of a local region in sequence space. • Neighboring sequences are shown for a central tetramer (ACGT) with substitutions in the first position to the north, second to the east, third position south, and fourth west.
DNA Word Encoding: • Vectors of the database are encoded by single stranded DNA sequences • DNA sequences use 4 bases, but we use a Base 12 encoding: • Each word has 12 distinct 5 base DNA subsequences • A number is encoded by a DNA sequence with consecutive blocks of 5 bases. • Redundant Encoding of each Database Element • use approx 10 identical single stranded DNAs per element • Word Design to Minimize DNA Annealing Mismatches: • To discriminate exact matches: • Distinct DNA words in block differ by at least 3 DNA bases • Data Base Values: • Each database element holds only a single bit value: • value is 1 <=> element is in the library. • Further values can easily appended to a DNA strand using flanking sequences
Each DNA Sequence uses distinct elements of Blocks Simple Example of DNA Code Word Design:
DNA Library Size: • Scaling of • Library Size with: • # Blocks • Words/Block • Library Size = [word count] block count • Initial Library: Size = 12 7 • Blocks = 7 • Words per Block = 12
DNA Library Design: • Used Extensive Computer Search for good DNA code words: • Minimize melting temperature difference (Tm) between words so hybridization of multiple words proceeds simultaneously • At least 3 base mismatches between word and complements in blocks • Avoid frame shift binding errors • DNA Sequences Used for Library: • Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 • AAACC AATCC AACCA AACCT AATCC ACACA AACCA • ACCAA ACACT ACATC ACCTA ACAAC ACCAT ACACT • ACTCT ATCAC ACCAT ACTAC ACCTT ATCTC ACTTC • ATCTC CAAAC ATTCC ATACC ATCCA CACAA ATCAC • CATAC CCATA CACTT CAAAC CAACT CATTC CATAC • CCTTA CCTAT CATAC CCATT CCATA CCATT CCAAA • CTACA CTCTT CCAAA CTCAA CTCAT CTAAC CTCTA • CTCAT CTTCA CTACT CTTCT CTTTC CTTCA CTTCT • TACCA TACCT TAACC TATCC TACTC TAACC TACTC • TCAAC TCCAA TCCTA TCACA TCCAA TCCTA TCCAT • TCCTT TCTTC TCTCT TCCAT TCTCT TCTAC TCTCA • TTTCC TTACC TTCAC TTCTC TTACC TTCCT TTACC • CATCG[GATC]C [-------------- insert 7 words as above---------------] AGATC[TCAC]ACCCTCCAC • 5' Bam HI Library Region Bgl II 3'
3D Fluid Bio-Technology using DNA Attached to Beads • DNA solid supported to Beads • Can use fluorescence tags • Bead sizes: 3 to 100 microns • Bead material: plastic or polystyrene • -Readout Methods for Beads: • Fluorescence activated cell sorter (FACS) • Example: MoFlo cell sorter • Fiber Optic Readout: Illuminata, Inc. • 60,000 fibers each of 3.5 microns • Etch ends of fibers and then add attachment chemistry to attach a bead to each fiber. -Combinatorial Libraries of Digital Tags appended to Natural DNA or RNA: (Lynx, Inc) • Generate Beads with Combinatorial Library of Digial Tags: • Lynx Tags: Each tag is a string 8 words chosen from alphabet of 8 words of 4 bases each. • They Synthesized via 8 stages of resin splitting • They Used FACS readout • Allowed differential analysis
Experiments at Duke University Chemistry LaboratoriesTentagel Beads: • 10 to 20 micron Tentagel Beads • Dr. Thom Labean Imaging the Tentagel Beads
Construction of a DNA library of size 127 Each element in initial database encodes a sequence of 7 numbers over {1,…,12} use a sequence of 7 consecutive 5 base DNA sequences. Synthesis on 50 milligrams of TentaGel M NH2 Resin ~ 108 Polystyrene Microbeads of 10 micrometer diameter ~ 1011 strands of DNA attached per bead: a total of ~ 1019 strands of DNA attached
Experimental Construction of • DNA Data Base Two Stage Experimental Synthesis: • Using mix-and-split methods on plastic microbeads, • we construct an initial DNA library of size: • 127 =35,831,808 • By combining pairs of initially synthesized library strands, • we square the size of the initial library to size: • (127)2 = 1214 = 1.28 x 1015
Construction of a DNA library of size 127 • Each element in initial database encodes a sequence of 7 numbers over {1,…,12} • use a sequence of 7 consecutive 5 base DNA sequences. • Used Mix-and-split DNA synthesis on plastic microbeads: Gives Exponential Growth in database size with number of steps: - Each splitting step generates a factor 10 more -Takes 7 steps of splitting and mixing to construct DNA database of size 127 - Limited by maximum number of beads. • Use ABI automatic synthesizer with • conventional phosphoramidite chemistry.
Construction of a DNA library of size 127 • Each element in initial database encodes a sequence of 7 numbers over {1,…,12} • use a sequence of 7 consecutive 5 base DNA sequences. • Synthesis on 50 milligrams of TentaGel M NH2 Resin • ~ 108 Polystyrene Microbeads of 10 micrometer diameter ~ 1011 strands of DNA attached per bead: a total of ~ 1019 strands of DNA attached Used Mix-and-split DNA synthesis on plastic microbeads: Gives Exponential Growth in database size with number of steps: - Each splitting step generates a factor 10 more -Takes 7 steps of splitting and mixing to construct DNA database of size 127 - Limited by maximum number of beads. • Use ABI automatic synthesizer with • conventional phosphoramidite chemistry.
Construction of a DNA library of size 1.28 x 1215 • Each element in the initial database encodes a sequence of 7 numbers in {1,…,12} combine pairs of the initially synthesized library strands Resulting DNA is a concatenation of two of the previously constructed strands Each element in squared database encodes sequence of 14 numbers in {1,…,12} • Squares the size of the initial library from 127 to size: • (127)2 = 1214> 1.28 x 1015 • Annealing & Ligation
Experiments at Duke LSRC Chemistry LaboratoryDNASynthesizer: • Prof. Michael Pirrung • DNA Synthesis for our Mix and Split Library Construction • Dr. Vipul Rana (Postdoc, Duke Chemistry Dept) • Loading Tentagel Beads into Synthesizer
Experiments of Associative Search in • DNA Database: -Use cell sorter to separate out DNA on attached beads with selected suffix sequence-PCR to amplify results -Optical Readout Via DNA Annealing Array
Experiments at Duke University Laboratories • Fluorescent Activated Cell Sorter (FACS) • Used to Separate Tentagel Beads with a given DNA Sequence • Operated by Assistant Prof Thom Labean and Dr. Joel Ross
Test Queries for Small Database • tag: 5' 3' • probe: 3' 5' • Most common tag sequence/high probability words (1 copy in 130 sentences) • tag: ATAC AACT AAAC TATC AATC CTAA • probe: TATG TTGA TTTG ATAG TTAG GATT • Moderate sentence probability/constant moderate word probability (1 copy in 8,304) • tag: CAAT TTAC ATCA CTTT ACAA TTTC • probe: GTTA AATG TAGT GAAA TGTT AAAG • Moderate sentence probability/variable word probabilities (1 copy in 8,304 sentences) • tag: ATAC CATA TCTA TATC TTCA TACT • probe: TATG GTAT AGAT ATAG AAGT ATGA • Least common tag sequence/low probability words (1 copy in 531,441 sentences) • tag: TTCA CATA CATT ACAT TTCA AAAC • probe: AAGT GTAT GTAA TGTA AAGT TTTG
NF F NF F 1b 1a NF NF F F 2a 2b NF NF F F 3a 3b Sorting Beads by FACS Control. 50:50 Control 1:10,000 Probe 1 Query (1:~130)
Experiments at Duke University LaboratoriesPCR Experiments (ongoing) • Dr. Thom Labean PCR Amplification of a Selected Data Element: • requires repeated stages of annealing on 35 base primers (the prefix or suffix of each composed DNA word). • To Insure Annealing stringency of PCR primers: • primers are only 35 bases • pairs of distinct DNA words in same block have > 3 base mismatch • Readout via a DNA annealing array.
High Rate Input & Output via DNA Chips • Individual DNA chips give highly parallel input/output over 2D surfaces. • Use for Input: • use of photosensitive DNA-on-a-chip technology: • 2D optical input is converted to DNA strands encoding the input data. • Use for Output: • Via hybridization at the sites with fluorescent labeled DNA, the output can be read as a 2D image. • Scaling of Individual DNA chips: • Each DNA chip can be optically addressed at up to 105 sites. • Projected to be millions of sites in the immediate future.
Optical Readout Via DNA Annealing Array: • Query strand: • binds to its complement on an element of the database • fluorescent labeled by primer extension with a fluorescent terminator nucleoside • binds via a complementary region to a site on probe array • is detected by fluorescent microscopy
Massively Parallel I/O Using Arrays of DNA Chips • I/O between: • conventional electronic media • and a "wet" database of DNA strands • (in solution or on solid support). • Propose Solution: Large Arrays of DNA Chips: • A few thousand chips can be placed on a 2D array compact enough so all chips can be addressed by a single optical system. • Gives potential of parallel synthesis of DNA at 108 sites or more to many billions of sites. • Massively parallel DNA input/output: • Has a potential for achieving a rate of I/O to convention optical/electronic media in the order of gigabit rates or more.
Massively Parallel I/O using Arrays of DNA ChipsTechnical Challenge: Error rates due to optically addressed base synthesis. • Most common error in optically addressed synthesis of DNA is a premature truncation and deletion in the growing strand. • Error rate in optically addressed DNA synthesis methods used for DNA chips is roughly 4% to 8% per base • Corresponds to an expected error in every 12 to 25 base pairs. • Application of DNA chips for I/O in BMC limited by current error rates. • Each DNA strand synthesized may be quite long (over 25 bases per strand). • Majority of DNA strands expect > one synthesis error. • Commercial DNA chips (proprietary Affymetrix technology) • Synthesis error rates not known for each type for possible error. • Utilize only a fraction of 105 optically addressable sites. • Current maximum: about 42,000 sites • Typical DNA chip: uses about 7,000 sites • Today: currently synthesis error rate seems not the dominant limiting factor, • Future: will impact scalability (addressable sites & strand length) of DNA chip technology.
DNA Synthesis Error ModelsSynthesis errors with independent base deletions (causing base bulges) will be first order approximated by an error model with a uniform, independent probability p of base replacement • Exact and Inexact Hybridization: • Short stretches of double-stranded DNA are depicted showing: • a) exact Watson-Crick(WC) complementary matching; • b) a mismatch (T-T) imbedded within a WC match region; and • c) a WC match region surrounding a bulged base (T). The bulged base can be described as a deletion from the left-hand strand or an insertion into the right-hand strand.
Error-Correction Methods From Computer Science Adapted to Biotechnology Methods for repairing faulty oligonucleotides contained within surface-bound probe arrays. • Use error-correcting codes for design of error-free probes. • Use "Error-Correction (EC)" DNA strands: • Specifically designed to bind both error-containing and error-free probes. • Error-Correction of Synthesized DNA Strands • Resulting in Overhangs. • Extra benefit: duplex probes containing single-stranded overhangs less error-prone than simple single-stranded probes.
Synthesizing EC Strands • Direct synthesis and purification: • small scale only. • Biased-Error Chemical Synthesis: • *** Recommended (details in paper) • The relative simplicity of the biased-error chemical synthesis approach makes it the most appealing of methods for generating diverse prefixes for EC strands. • Other Methods for Generating Diverse Prefix for EC Strands: • Mutagenisis via Polymerase Enzymes. • DNA Self Assembly.
Tasks: • Computer Preprocessing of Image Database • Image segmentation • wavelet transform • vector quantization • Computer Simulation of DNA Search • Experimental Synthesis of DNA Library • Computer Search for Sequences Defining DNA Library • Two Stage Synthesis of DNA Library • Experimental Tests of Associative Search • select and amplify chosen DNA library element (Status:Tested) • readout results