Download

1 / 25
530 likes | 2.32k Views
Flash Translation Layer (FTL). March 28, 2011 Sungjoo Yoo Embedded System Architecture Lab. Agenda. Introduction to FTL LAST. [Source: J. Lee, 2007]. Typical Flash Storage. Both # of Flash i/o ports and controller technology determine Flash performance. Host (PC). Intel SSD.

E N D
Flash Translation Layer (FTL) March 28, 2011 Sungjoo Yoo Embedded System Architecture Lab. ESA, POSTECH, 2011
Agenda • Introduction to FTL • LAST ESA, POSTECH, 2011
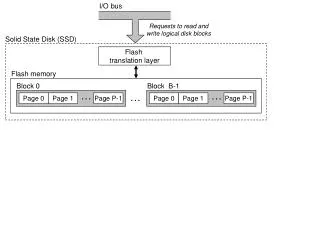
[Source: J. Lee, 2007] Typical Flash Storage • Both # of Flash i/o ports and controller technology determine Flash performance Host (PC) Intel SSD I/O Interface(USB, IDE, PCMCIA) NANDFlash Controller FTL runs on the controller FTL runs on the controller ESA, POSTECH, 2011
[Source: J. Lee, 2007] Flash Translation Layer (FTL) • A software layer emulating standard block device interface Read/Write • Features • Sector mapping • Garbage collection • Power-off recovery • Bad block management • Wear-leveling • Error correction code (ECC) ESA, POSTECH, 2011
Single Page Write Case • Remember “erase-before-write” means “no overwrite”! (tR + tRC + tWC + tPROG )*(# pages/block) + tERASE = (25us + 105.6us*2 + 300us)*64 + 2ms = 36.32ms for a single-page (2KB) write operation ESA, POSTECH, 2011
Replacement Block Scheme [Ban, 1995] • In-place scheme • Keep the same page index in data and update blocks Called data (D) block Called update (U) block (or log block) D block U block 1 Previously, two single-page write operations take 2 x 36.32ms = 72.63ms ~90X reduction! Two single page-write operations take 2 x (tWC + tPROG ) = 2 x (105.6us + 300us) = 0.81ms ESA, POSTECH, 2011
Replacement Block Scheme [Ban, 1995] • In-place scheme • Keep the same page index in data and log blocks D block U block 1 U block 2 Advantage Simple Disadvantages Utilization is low Violate the sequential write constraint ESA, POSTECH, 2011
Log Buffer-based Scheme [Kim, 2002] • In-place (linear mapping) vs. out-of-place (remapping) schemes D block U block 1 U block 2 D block U block 1 U block 2 In-place scheme +No need to manage complex mapping info - Low U block utilization - Violation of sequential write constraint Out-of-place scheme + High U block utilization + Sequential write - Mapping information needs to be maintained ESA, POSTECH, 2011
Garbage Collection (GC) D block U block 1 U block 2 No more U block! Perform garbage collection to reclaim U block(s) by erasing blocks with many invalid pages ESA, POSTECH, 2011
[Kang, 2006] Three Types of Garbage Collection • Which one will be the most efficient? ESA, POSTECH, 2011
Garbage Collection Overhead Full merge cost calculation Assumptions 64 page block tRC = tWC = 100us tPROG = 300us tERASE = 2ms Max # of valid page copies = 64 # block erases = 3 Full merge operations D block Free block U block 1 U block 2 Runtime cost = 64*(tRC+tWC+tPROG)+3*tERASE = 64*(100us*2+300us)+3*2ms = 38ms X X X Valid page copies may dominate runtime cost minimize # valid page copies ESA, POSTECH, 2011
Three Representative Methods of Flash Translation Layer • FAST [Lee, 2007] • Two types of log block • A sequential write log block to maximize switch merges • Random write log blocks cover the other write accesses • Superblock [Kang, 2006] • A group of blocks is managed as a superblock • Linear address mapping is broken within a superblock to reduce # of valid page copies in GC • LAST [Lee, 2008] • Two partitions in random write log blocks • Hot partition more dead blocks reduction in full merge ESA, POSTECH, 2011
[Lee, 2008] LAST • Observations • Typical SSD accesses have both random and sequential traffics • Random traffics can be classified into hot and cold ESA, POSTECH, 2011
[Lee, 2008] LAST Scheme ESA, POSTECH, 2011
[Lee, 2008] Locality Detection:Random vs. Sequential • Observations • Short requests are very frequent (a) • Short requests tend to access random locations (b) • Long requests tend to access sequential locations (b) • Threshold of randomness • 4KB from experiments ESA, POSTECH, 2011
[Lee, 2008] LAST Scheme < 4KB >= 4KB ESA, POSTECH, 2011
[Lee, 2008] Why Hot and Cold? • Observation • A large amount of invalid pages (>50%) occupy random log buffer space • They are mostly caused by hot pages • Problem • Invalid pages are distributed over random log buffer space, which causes full merges (expensive!) ESA, POSTECH, 2011
Aggregating Invalid Pages due to Hot Pages • An example trace • 1,4,3,1,2,7, 8, 2, 1, … • Single random buffer partition suffer from distributed invalid pages • In LAST method, Hot partition aggregates invalid pages --> full merges can be reduced. In addition, full merges are delayed ESA, POSTECH, 2011
Temporal Locality: Hot or Cold? • Update interval (calculated for each page access) = Current page access time – last page access time • If update interval < k (threshold) • Hot (means frequent writes) ESA, POSTECH, 2011
[Lee, 2008] LAST Scheme < 4KB >= 4KB ESA, POSTECH, 2011
Garbage Collection in LAST:Step 1 Victim Partition Selection • Basic rule • If there is a dead block in Hot partition, we select Hot partition as the victim partition • Else, we select Cold partition as the victim • Demotion from Hot to Cold page • If there is a log block whose updated time is smaller than a certain threshold time, age threshold (i.e., old enough), then we select Hot partition as the victim ESA, POSTECH, 2011
Garbage Collection in LAST:Step 2 Victim Block Selection • Case A: Victim partition = Hot partition • If there is a dead block, select it • Else, select a least recently updated block • Case B: Victim partition = Cold partition • Choose the block with the lowest (full) merge cost (in the merge cost table) • Na: associativity degree, Np: # valid page copies • Cc: page copy cost, Ce: erase cost ESA, POSTECH, 2011
Adaptiveness in LAST • Hot/cold partition size (Sh, Sc), temporal locality threshold (k), age threshold, etc. are adjusted at runtime depending on the given traffics • Nd = # dead blocks in Hot partition • Uh = utilization of Hot partition (# valid pages / # total pages) • One example of runtime policy • If Nd is increasing, then reduce Sh since too many log blocks are assigned to Hot partition • There are several more policy examples in the paper • Comments: They do not seem to be extensive. Thus, they can be improved further ESA, POSTECH, 2011
Experimental Results • Full merge cost is significantly reduced by LAST • Many dead blocks are created GC with the lowest cost (only erase is needed)
Reference • [Ban, 1995] A. Ban, Flash File System, US Patent, no. 5,404,485, April 1995. • [Kim, 2002] J. Kim, et al., “A Space-Efficient Flash Translation Layer for compactflash Systems”, IEEE Transactions on Consumer Electronics, May 2002. • [Kang, 2006] J. Kang, et al., “A Superblock-based Flash Translation Layer for NAND Flash Memory”, Proc. EMSOFT, Oct. 2006. • [S. Lee, 2007] A Log Buffer-Based Flash Translation Layer Using Fully-Associative Sector Translation, ACM TECS, 2007 • [Lee, 2008] S. Lee, et al., “LAST: locality-aware sector translation for NAND flash memory-based storage systems”, ACM SIGOPS Operating Systems Review archive, Volume 42 , Issue 6, October 2008. ESA, POSTECH, 2011