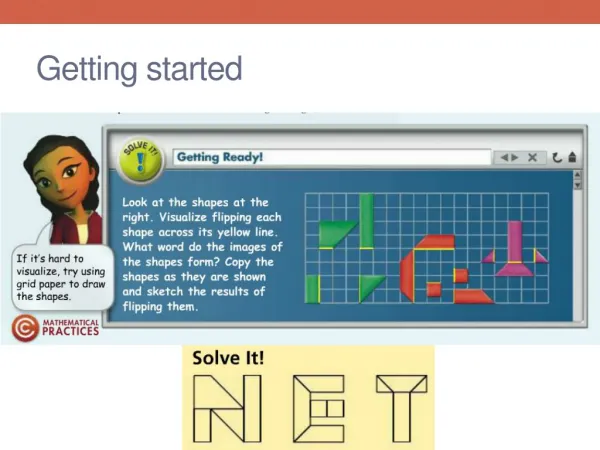
Download

1 / 17

E N D
Some stories to get us started “Smoking causes lung cancer.” You may have heard this before. Well, how the heck do they know this? Through careful study and observation, it has been established that smokers have a greater incidence of lung cancer than the rest of the population. Statistics, in general, is part of the careful study and observation I mentioned above. “Television advertising is better than newspaper ads when you want to reach the younger generation.” Again, who says? The answer, in part, comes from those who use the methods of statistics. Statistics are used to back up claims people make about the world (stats are used for other things as well, as we will see).
In statistics class we use certain “tools.” The tool kit looks an awful lot like math, with equations and graphs and tables and variables and the like. It is math. BUT, you can do this because for the most part all we do is add, subtract, multiply and divide. Occasionally we will take the square root of a number. We will use Microsoft Excel to do some calculations for us as well. Statistics is really about ideas. I am convinced that if you can work with the ideas, the math will follow. (Hey Parker, do you have statistics to back up your claim? NO, I have not done the study – but I am convinced!) There are two main areas of statistics as a topic of study: descriptive statistics and inferential statistics. Let’s look briefly at each.
Descriptive Statistics Example: You are probably aware of the distribution of test scores from an exam. The instructor describes properties of the data. You see how many A’s, B’s and such were earned. You might be told the average grade. Why is this a big deal? Well, you want to know how you compare to others. Describing data is a big part of statistics.
Inferential Statistics Inferential Statistics is a method used when only a sample from a population has been drawn, but we want to make statements about the larger population. Any cooks reading this? In order to tell if a pot of soup is ready to go, is taking a sample okay? Sure it is, but first make sure you have stirred the soup to mix in the ingredients. In statistics, we feel pretty good about samples as long as we have “mixed” things well.
At this stage of our study of statistics we will take it on faith that inference can be done and is useful. Experts have studied this carefully. Digress: Some guy named Ptolemy (silent P) was considered an expert in his day. He thought the sun revolved around the earth. Copernicus came around later and showed that the earth rotates around the sun. Ptolemy was no longer an expert. Are experts today wrong? Deep question, huh? Let’s not worry too much about why inference works. Let’s just spend time learning the methods in the book and we can leave the deeper stuff for another semester.
Define: variable, data set, value • Definition: variable – a characteristic of an item or individual. An example is faculty salary. Faculty salary is a variable because not every person has the same salary. • If you have collected information about a characteristic or some aspect from many people or things then you have a dataset. • Each person or thing (element) has their value on the variable recorded.
Examples • Examples: • values for income • 10,000 or 27,352 or 1,000,000 • values for sex • 1 = male, 2 = female.
Population Often in statistics we are interested in a group. The group may be large, or even huge! Plus we want to be able to make statements or draw conclusions about the group. A population is the set of “whats” or “whoms” the researcher wants to study or know something about. So, the population is the main group we want to know about The unit of analysis is what we call the whats or the whoms. An element is a single entity of the population.
Examples Say we want to study faculty salaries at WSC. Our research topic is faculty salaries. The population is WSC faculty. The unit of analysis is individual faculty. Parker is an element of the population, as is Lutt, Paxton, Nelson, and others. Another example might be we want to study the budgets of state governments. The population is all 50 states. The unit of analysis is the states. What are the elements? (Did you say something like Ohio, Nebraska, Iowa….?) Our interest may be people, companies, states, etc…
Sample Many times in a study all the elements of the population will not be observed, so a sample is said to have been taken. A sample is a subset of a population – just part of the population.
Parameters and Statistics You probably noticed this class is called Business Statistics. The idea I want to have you think about here is a more specific understanding of the world statistic, and to introduce you to what a parameter is all about. You are probably familiar with the idea known as the average or mean of some numbers. The mean is an example of a parameter in the context of a population. A parameter is a descriptor about some aspect of the population. But, if the mean is calculated from a sample of data the mean is then a statistic! A statistic is a descriptor about some aspect of a sample. NOTE: Inference is about using sample statistics to learn about population parameters.
Data As we get started in this chapter say as a research project we want to learn more about faculty at WSC. Say we gather information from faculty about 1) what is their highest educational degree, 2) how often they cuss during the day, and 3) how long they have been in Wayne. Some data collected from faculty might look like: Faculty Degree Cuss In Wayne Person 1 PhD 0 22 Person 2 EdD 0 35 Person 3 MFA 0 15 Person 4 PhD 237 13
Categorical variable The variable Degree in our example is an example of a categorical variable. The data, or observed values, from the people on the variable just yield a categorical response. IN my example I have things like PhD, MFA, and EdD. Note that sometimes in a data set numbers may be used to express the values on the variable, but all we really have are categories of responses. For example, we could have 1 = EdD, 2 = PhD, 3 = MFA and in the data set all you would see are the numbers.
Numerical variable In our example the variables how often they cuss during the day and how long they have been in Wayne are numerical variables. The data, or observed values, from the people on the variables yield a numerical response. Numerical variables can be either discrete or continuous.
Discrete and Continuous variables Number line A way I like to think about the difference between discrete and continuous variables is to think of the number line. Each “mark” I have on the left might be a whole number (and I should have put more “marks” in). If the variable can only take on the values of the marks then the variable is discrete. An example might be how many customers visited the store during the lunch hour. We could have had 0, or 1, or 2, or 3, and so on. (note: a statistic we might calculate might have a value that does not land on a mark – no big deal – the variable is still discrete.)
Discrete and Continuous variables Still thinking about the number line on the previous screen, continuous variables might have values at the marks, but may also have values off the marks. For example maybe the store has a fountain pop machine and we are interested in how many ounces are sold during the lunch hour. Examples might include, 6, 10 or 122.376589872 ounces. If all the number line, even between marks, can be possible values for a variable then the variable is continuous. Note: we have a hard time measuring ounces of pop as closely as I suggested, but the idea is sound and the variable would be continuous. The example from the faculty research has a question about how long they have been in Wayne. That really is a continuous variable, although for practical reasons we do not calculate the time down to the last second. We might round to years.