Download
1 / 29
310 likes | 530 Views
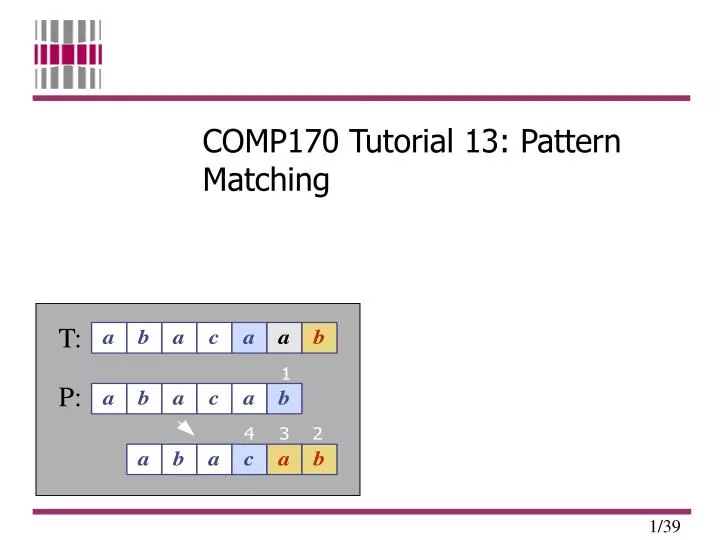
COMP170 Tutorial 13: Pattern Matching. T:. P:. Overview. 1. What is Pattern Matching? 2. The Naive Algorithm 3. The Boyer-Moore Algorithm 4. The Rabin-Karp Algorithm 5. Questions. 1. What is Pattern Matching?. Definition:

E N D
Overview 1. What is Pattern Matching? 2. The Naive Algorithm 3. The Boyer-Moore Algorithm 4. The Rabin-Karp Algorithm 5. Questions
1. What is Pattern Matching? • Definition: • given a text string T and a pattern string P, find the pattern inside the text • T: “the rain in spain stays mainly on the plain” • P: “n th” • Applications: • text editors, Search engines (e.g. Google), image analysis
String Concepts • Assume S is a string of size m. • A substring S[i .. j] of S is the string fragment between indexes i and j. • A prefix of S is a substring S[0 .. i] • A suffix of S is a substring S[i .. m-1] • i is any index between 0 and m-1
S a n d r e w 0 5 Examples • Substring S[1..3] == "ndr" • All possible prefixes of S: • "andrew", "andre", "andr", "and", "an”, "a" • All possible suffixes of S: • "andrew", "ndrew", "drew", "rew", "ew", "w"
2. The Naive Algorithm • Check each position in the text T to see if the pattern P starts in that position T: a n d r e w T: a n d r e w P: r e w P: r e w P moves 1 char at a time through T . . . .
Algorithm and Analysis • Brutal force continued
The brute force algorithm is fast when the alphabet of the text is large • e.g. A..Z, a..z, 1..9, etc. • It is slower when the alphabet is small • e.g. 0, 1 (as in binary files, image files, etc.) • Example of a worst case: • T: "aaaaaaaaaaaaaaaaaaaaaaaaaah" • P: "aaah" • Example of a more average case: • T: "a string searching example is standard" • P: "store" continued
Reverse naive algorithm • Why not search from the end of P? • Boyer and Moore Reverse-Naive-Search(T,P) 01 for s ¬ 0 to n – m 02 j ¬ m – 1 // start from the end 03 // check if T[s..s+m–1] = P[0..m–1] 04 while T[s+j] = P[j] do 05 j ¬ j - 1 06 if j < 0 return s 07 return –1 • Running time is exactly the same as of the naive algorithm…
3. The Boyer-Moore Algorithm • The Boyer-Moore pattern matching algorithm is based on two techniques. • 1. The looking-glass technique • find P in T by moving backwards through P, starting at its end
2. The character-jump technique • when a mismatch occurs at T[i] =/= P[m-1] • the character in pattern P[m-1] is not the same as T[i] • There are 2 possible cases. T x i P b
Case 1 • If P contains x somewhere, then try to shift P right to align the last occurrence of x in P with T[i]. T T ? ? a a x x i P P x x b b c c
Case 2 • If the character T[i] does not appear in P, then shift P to align P[0] with T[i+1]. T T ? ? a a x x ? i inew P P d d b b c c 0 No x in P
Case 3 • If T[i] = P[m-1] and the match is incomplete, align T[i] with the last occurrence of T[i] in P. T T ? ? a a x x ? inew i P P a a a a b b c c
Boyer-Moore Example (1) T: P:
Boyer-Moore algorithm • To implement, we need to find out for each character c in the alphabet, the amount of shift needed if P[m-1] aligns with the character c in the input text and they don’t match. Example: Suppose the alphabet is {a, b,c} and the pattern is ababbb. Then, shift[c] = 6 shift[a] = 3 shift[b] = 1 This takes O(m + A) time, where A is the number of possible characters. Afterwards, matching P with substrings in T is very fast in practice.
Analysis • Boyer-Moore worst case running time is O(nm + A) • But, Boyer-Moore is fast when the alphabet (A) is large, slow when the alphabet is small. • e.g. good for English text, poor for binary • Boyer-Moore is significantly faster than brute force for searching English text.
Fingerprint idea • Assume: • We can compute a fingerprint f(P)of P in O(m) time. • If f(P)¹ f(T[s .. s+m–1]), then P ¹ T[s .. s+m–1] • We can compare fingerprints in O(1) • We can compute f’ = f(T[s+1.. s+m]) from f(T[s .. s+m–1]), in O(1) f’ f
Algorithm with Fingerprints • Let the alphabet S={0,1,2,3,4,5,6,7,8,9} • Let fingerprint to be just a decimal number, i.e., f(“1045”) = 1*103 + 0*102 + 4*101 + 5 = 1045 Fingerprint-Search(T,P) 01 fp ¬ compute f(P) 02 f ¬ compute f(T[0..m–1]) 03 for s ¬ 0 to n – m do 04 if fp = f return s 05 f ¬ (f – T[s]*10m-1)*10 + T[s+m] 06 return –1 T[s] new f f T[s+m] • Running time O(m+n) • Where is the catch?
Using a Hash Function • Problem: • we can not assume we can do arithmetics with m-digits-long numbers in O(1) time • Solution: Use a hash function h = f mod q • For example, if q = 7, h(“52”) = 52 mod 7 = 3 • h(S1) ¹h(S2) Þ S1¹S2 • But h(S1) = h(S2) does not imply S1=S2! • For example, if q = 7, h(“73”) = 3, but “73” ¹ “52” • Basic “mod q” arithmetics: • (a+b) mod q = (a mod q + b mod q) mod q • (a*b) mod q = (a mod q)*(b mod q) mod q
Preprocessing and Stepping • Preprocessing: • fp = P[m-1] + 10*(P[m-2] + 10*(P[m-3]+ … … + 10*(P[1] + 10*P[0])…)) mod q • In the same way compute ft from T[0..m-1] • Example: P = “2531”, q = 7, what is fp? • Stepping: • ft = (ft–T[s]*10m-1 mod q)*10 + T[s+m]) mod q • 10m-1 mod q can be computed once in the preprocessing • Example: Let T[…] = “5319”, q = 7, what is the corresponding ft? T[s] new ft ft T[s+m]
Rabin-Karp Algorithm Rabin-Karp-Search(T,P) 01 q¬ a prime larger than m 02 c ¬10m-1mod q //run a loop multiplying by 10mod q 03 fp ¬ 0; ft ¬ 0 04 for i¬ 0 to m-1 // preprocessing 05 fp ¬ (10*fp + P[i]) mod q 06 ft ¬ (10*ft + T[i]) mod q 07 for s ¬ 0 to n – m // matching 08 if fp = ft then // run a loop to compare strings 09 if P[0..m-1] = T[s..s+m-1] return s 10 ft ¬ ((ft – T[s]*c)*10 + T[s+m]) mod q 11 return –1 • How many character comparisons are done if T = “2531978” and P = “1978”?
Analysis • If q is a prime, the hash function distributes m-digit strings evenly among the q values • Thus, only every q-th value of shift s will result in matching fingerprints (which will require comparing stings with O(m) comparisons) • Expected running time (if q > m): • Outer loop: O(n-m) • All inner loops: • Total time: O(n-m) • Worst-case running time: O((n-m+1)m)
Rabin-Karp in Practice • If the alphabet has d characters, interpret characters as radix-d digits (replace 10 with d in the algorithm). • Choosing prime q > m can be done with randomized algorithms in O(m), or q can be fixed to be the largest prime so that 10*q fits in a computer word. • Rabin-Karp is simple and can be easily extended to two-dimensional pattern matching.
Question 1 • What is the worst case complexity of the Naïve algorithm? Find an example of the worst case. • What is the worst case complexity of the BM algorithm? Find an example of the worst case.
Question 2 • Illustrate how does BM work for the following pattern matching problem. • T: abacaabadcabacabaabb • P: abacab
Answer to question 1 • Example of a worst case for Naïve algorithm: • T: "aaaaaaaaaaaaaaaaaaaaaaaaaah" • P: "aaah“ • Time complexity O(mn)
BM Worst Case Example • T: "aaaaa…a" • P: "baaaaa“ • Complexity • O(mn+A) T: P:
T: P: Answer to question (2)






















