Download

1 / 1
10 likes | 108 Views
Research Overview. Research Focus. Learning and Inference Paradigms for Natural Language Understanding. Assessing Trustworthiness.

E N D
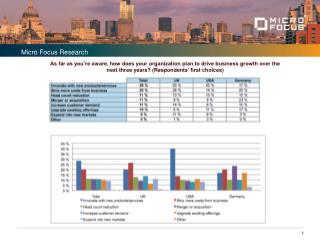
Research Overview Research Focus Learning and Inference Paradigms for Natural Language Understanding Assessing Trustworthiness Our research focuses on the computational foundations of intelligent behavior. We develop theories and systems pertaining to intelligent behavior using a unified methodology, at the heart of which is the idea that learning has a central role in intelligence. We investigate the role of learning in supporting intelligent inference and use this understanding to develop systems that learn and make intelligent inferences in complex domains. Such systems must acquire the bulk of their knowledge from raw, real world data, and behave robustly when presented with new, previously unseen, situations. We have focused on the problems of natural language understanding and intelligent access to textual information, developing the underlying machine learning theory needed to make progress in these challenging areas hand in hand with developing state-of-the-art software tools to solve a range of Natural Language Processing tasks. Although much work in NLP has focused on determining what a document means, we also must know whether or not to believe it. We have started to develop techniques to assess both the reliability of sources of information on the internet – organizations and their associated web sites, or the writings of individual people – and to assess the reliab-ility of individual statements in a domain of interest (such as the medical domain). Our framework makes use of CCMs and allows us to incorporate users’ prior knowledge into TruthFinders algorithms. A collection of Classifiers; Log-linear models (HMM, CRF) or a combination Penalty for violating the constraint. Knowledge Base Transliteration Companion Task– binary supervision Transliteration Target Task – alignment structure (Soft) constraints component I t a l y I t a l y Yes/No Weight Vector for “local” models How far y is from a “legal” assignment ט ט ה ה א י ל י א י ל י This work complements research on Evidence Search and on detecting sensitive information in large document collection, combining analyses of the textcontent and of the linkstructure connecting these documents on the internet to assess the trustworthiness of different sources, and even of individual statements. Making complex decisions in real world problems often involves assigning values to sets of interdependent variables where the expressive dependency structure influences what assignments are possible. Constrained Conditional Models (CCMs; a.k.a. Integer Linear Programming formulation of NLP problems) is a learning and inference framework that augments the learning of conditional (probabilistic or discriminative) models with declarative constraints as a way to support decisions in an expressive output space while maintaining modularity and tractability of training and inference and facilitating the use of background knowledge. Interpretation Task Decisions Learner (TDL) Language Learner(LL) Find Obama in the Hebrew Wikipedia Learning to predict structure requires highly specialized supervision – a major challenge in scaling machine learning techniques to real world natural language processing problems. We investigate methods that allow learning models for structured prediction using an indirect supervision signal which is considerably easier to obtain and suggest indirect learning protocols for common NLP learning scenarios. We achieve this by identifying companion problems, which allow straightforward induction or generation of binary labels for the same inputs as the structured prediction problem. This binary signal is used in our LCLR learning algorithm as feedback for a structured prediction component, using the intuitive constraint that positive labels from the binary signal must correspond to well-formed structures in the structured prediction problem, while negative binary labels must correspond to poorly-formed structures. Our approach achieves improved performance on problems such as transliteration, paraphrasing, recognizing textual entailment, and semantic parsing (inducing a logical form from natural language text). Negative examples cannot have a good structure, Predicted Research Expertise Correct Our work addresses foundational questions in learning, knowledge representation and reasoning, experimental paradigms and large scale system development, drawing on methods from theoretical computer science, probability and statistics, artificial intelligence, linguistics, and experimental computer science. We are driven both by longer term goals to understand and develop capabilities for natural language comprehension, and by challenging shorter term applications in the area of information extraction and knowledge access. In terms of "traditional" research areas our work falls mostly into Natural Language Processing and Machine Learning, as well as Information Extraction and Data Analytics in general. Some of our more recent foci include the development of models that bridge our work on Semantic Parsing and Psycholinguistics research on Natural Language Acquisition, and a new line of work on Natural Language Understanding in Context – transforming natural language instructions into actionable models. A key example of the latter direction is a program that learns how to play strategic games by following written instructions. Machine Learning Support for NLP and Information Extraction We have developed Learning-Based Java to make programming with Machine Learning paradigms easier for non-expert users. We have also developed state of the art NLP and Information Extraction tools that are widely used. You can download our software and see real-time demos at: http://L2R.cs.uiuc.edu/~cogcomp/ Negative examples restrict the space of hyperplanes supporting the decisions for x The feasible structures of an example Tracking Entities across Documents Modeling Children's Language Acquisition Learning from Environment Response The BabySRL Project: Using NLP and Machine Learning techniques, we are investigating models of language acquisition by children. We propose that shallow but abstract representations of sentence-structure guide early sentence interpretation, and have built computational models that mirror key observations of child language learning. Our joint work with a team of psycholinguists at the University of Illinois focuses on the acquisition of verb-argument structures by investigating simple language features involving the number and order of nouns in a sentence. Language experiments with children support the proposal that toddlers build partial structures that preserve the number and order of nouns in a sentence, but leave open the possibility that children's behavior stems from different underlying representations. In our experiments with a computational model of semantic-role labeling (SRL), whose representations of sentence-structure are under our control, we simulate the learning process using unlabeled data and a seed set of concrete nouns. By using only the shallow structures consistent with the proposed language acquisition model, we can assess the model’s predictions on unseen data (sentences with verbs not used in the training process). With the ordered set of noun representation, our system reproduces errors seen in child experiments, providing an independent source of evidence for the psycholinguistic analysis. Our Reading in Context work investigates a new approach to semantic interpretation. We assume an external actionable context such as the real world or simulated environment and text containing instructions for a task in that actionable environment. We evaluate the ability of a reasoning agent to interpret the text by observing the actions it takes in that context, that its performance after reading the instructions. Natural Language Instruction “...there are only a few rules, like for example, you can play any card on an empty freecell. You don't want to do this too much or you'll run out of freecells and get stuck..." Game API: source of Labeled solitaire moves We Are... Graduate Students Identifying entities in text and linking different mentions of those entities to the correct individuals they could represent, is an open research problem. We have applied our machine learning expertise to develop applications for recognizing when a given word or phrase represents an entity of interest (NER), and to resolving co-referent mentions within and across documents and disambiguate mentions of entities with similar or identical names (co-reference resolution). Our Wikifier maps phrases in text documents to the corresponding entries on Wikipedia. Head • Ming-Wei Chang • Michael Connor • Quang Do • Dan Goldwasser • Gourab Kundu • Jeff Pasternack • Lev Ratinov • Nick Rizzolo • Alla Rozovskaya • Vivek Srikumar • Yuancheng Tu • V.G. Vinod Vydiswaran • Dan Roth • James Clarke • Yee Seng Chan • Shankar Vembu • Mark Sammons • Joshua Gioja • Michael Paul A straight forward approach to this problem is to convert the textual instructions into complete logical formulas that can be used as a rule based system in the relevant world context. Unfortunately semantic parsing, the process of converting text into its logical interpretation, is a very difficult task, and providing the supervision required to train a semantic parser for each domain is infeasible. When a semantic parser is available, it will generate some fraction of incorrect formulae, meaning that the induced knowledge will be noisy and/or incomplete. Postdoctoral Researchers Textual Inference and Knowledge Representation We introduce a new approach in which the interpretation is not used directly in decision making but rather integrated into a real world learning task, thusallowing the interpretation to change according to real world response to the actions of the learned model. Our experimental setting is an automated Freecell Solitaire player, which augments its knowledge resources using rules induced from natural language text instructions available on the world wide web.The system converts text to logical formulae fragments, which are used as features for task learning, yielding a representation of the rules of Freecell solitaire. We evaluate our model by observing the task improvement due to the generated features, and observe significant improvement due to the use of natural language instructions. Research Scientist Our research into textual inference, a core capability required by many NLP applications, has led us to develop intermediate knowledge representations that facilitate learning and inference in complex domains. In addition to multi-view data representations supporting flexible run-time inference, we have formulated a model that encapsulates specialized knowledge capabilities as metrics. These compare arbitrary constituents of text based on standard NLP analytics, simplifying development and integration. The diagram to the right shows a multi-view representation of a textual entailment pair, together with color-coded edges corresponding to the outputs of specialized metrics. The green edges linking SRL constituents indicate a positive match, while the red edges connecting Numerical Quantity constituents indicate that the metric reports a mis-match. Research Programmers Undergraduate Students • Nikhil Johri Our Research is supported by NSF, NIH, DARPA, DHS, ONR as well as Boeing, Motorola, and Google.