Understanding Hadoop's MapReduce Execution Framework: A Comprehensive Overview
This guide provides an in-depth understanding of the MapReduce execution framework, detailing the roles of HDFS, Namenode responsibilities, and the MapReduce algorithm. Learn how input data is split into individual files, the significance of mappers, reducers, combiners, and partitioners, as well as job configuration best practices. Gain insights into metrics and monitoring tools available for performance optimization, including transparent scheduling and fault tolerance. This resource is ideal for those seeking to leverage Hadoop's capabilities for data processing.


Understanding Hadoop's MapReduce Execution Framework: A Comprehensive Overview
E N D
Presentation Transcript
Execution Framework Based on the text by Jimmy Lin and Chris Dryer; and on the yahoo tutorial on mapreduce at http://developer.yahoo.com/hadoop/tutorial/index.html
Execution Framework: HDFS • Namenode responsibilities: • Namespace management: file name, locations, access privileges etc. • Coordinating client operations: Directs clients to datanodes, garbage collection etc. • Maintaining the overall health of the system: replication factor, replica balancing etc. • Namenode does not take part in any computation
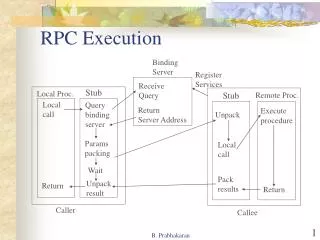
Execution Framework: MapReduce • AMapReduce job use individual files as a basic unit for splitting input data. • Workloads are batch-oriented, dominated by long streaming reads and large sequential writes. • Applications are aware of the distributed file system. • File system can be implemented in an environment of cooperative users. • See figure 2.6 and understand • Operations: (mapper, reducer) {combiner} [partitioner, shuffle and sort] : these operations have specific meaning in the MR context. You must understand it fully before using them. • Finally study the job configuration: items you can specify declaratively and how to specify these attributes.
MapReduce Algorithm • Module 4 in yahoo tutorial • Read every line of: Functional programming section • Understand the mapper, reducer and most importantly the driver method (job config) • Module 5: Read the details about partitioner • Metrics • Monitoring: web monitoring possible
MapReduce Fundamentals: Text • Figure 2.1 map and fold • Map is a “transformation” function that can be carried out in parallel: can work on the elements of list in parallel • Fold is an “aggregation” function that has restrictions on data locality: requires elements of the list to be brought together before the operation • For operations that are associative and commutative, significant performance can be achieved by local aggregation and sorting. • User specifies the map&reduce operations and the execution framework coordinates the execution of the programs and data movement.
MapReduce • imposes <key, value> structure to data • Example 1: <URL, content at this URL> • Example 2: <docid, doc> • map: (k1, v1) → [(k2, v2)] • reduce: (k2, [v2]) → [(k3, v3)] • Map generates intermediate values, and they are implicitly operated using “group by” operator and are in order within a given reducer. • Each reducer output is written into a external file. • Reduce method is called once for each key value in the data space to be processed by reduce. • Mapper with identity reducer is essentially a sorter. • Typical Mapreduce processes data in distributed file system and writes back to the same file system.
Other Data Models • Data Storage: output from MR could go into a sparse multi-dimensional table called BigTable in Google’s system. • The Apache open source version is HBASE. • HABSE is a column based table. • Rows, column families each with many columns. • Data is stored normalized in a relational schema. • Data in Hbase is not normalized by choice and by design. • Column families are stored together and storage methods optimized for this.
Scheduling • Very interesting since there are many tasks to manage. • Transparent, policy-driven, predictable multi-user scheduling • Speculative scheduling: Due to the barrier between M and R, the map is only as fast as the slowest Map; managing stragglers • But how to handle skew in the data: better local aggregation
Other functions • Data/operation co-location • Synchronization: copying into reduce as the map is going on; existence of barrier between map and reduce • Error and fault-tolerance: hardware as well as software
Other Operations • Partitioners: Partitioners divide the intermediate key space and assign the parts to the reducers. • Combiners are optimization means by which local aggregation can be done before sort and shuffle. • Thus a complete MR job consists of mapper, reducer, combiner, partitioner and job configuration; rest is taken care of by the execution framework.