Download

1 / 23
250 likes | 401 Views
Computing Word-Pair Antonymy. * Saif Mohammad *Bonnie Dorr φ Graeme Hirst *Univ. of Maryland φ Univ. of Toronto EMNLP 2008. Introduction. Antonymy : pair of semantically contrasting words. Ex: Strongly antonymous: Hot Cold Semantically contrasting: Enemy Fan

E N D
Computing Word-Pair Antonymy *Saif Mohammad *Bonnie Dorr φGraeme Hirst *Univ. of Maryland φUniv. of Toronto EMNLP 2008
Introduction • Antonymy: pair of semantically contrasting words. • Ex: Strongly antonymous: HotCold Semantically contrasting: EnemyFan Not antonymous: PenguinClown
Usage • Detecting contradictions • Detecting humor • Automatic creation of thesaurus
Problem Definition • Given a thesaurus, find out the antonymous category pairs. • Assign the degree of antonymy to each pair of antonymous categories.
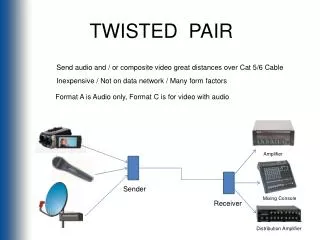
Hypothesis(1) • The Co-occurrence Hypothesis of Antonyms • Antonymous word pairs occur together much more often than other word pairs.
Hypothesis(1) • Empirical proof: • 1,000 antonymous pairs from Wordnet • 1,000 randomly generated word pairs • Use BNC as corpus, set window size 5. • Calculate the MI for each word pairs and average it
Hypothesis(2) • The Distributional Hypothesis of Antonyms • Antonyms occur in similar contexts more often than non-antonymous words • Ex work: activity of doing job play: activity of relaxation
Hypothesis(2) • Empirical proof: • Use the same set of word pairs in hypothesis(1) • Calculate the distributional distance between their categories
Distributional Distancebetween Two Thesaurus Categories c1,c2: thesaurus category I(x,y):pointwise mutual information between x and y T(c):the set of all words w such that I(c,w)>0
Method • Determine pairs of thesaurus categories that are contrasting in meaning • Use the co-occurrence and distributional hypotheses to determine the degree of antonymy of word pairs
Method • 16 affix rules were applied to Macquarie Thesaurus • 2,734 word pairs were generated as a seed set. • Exceptions: sectXinsect • Relatively few
Method • 10,807 pairs of semantically contrasting word pairs from WordNet
Method • If any word in thesaurus category C1 is antonymous to any word in category C2 as per a seed antonym pair, then the two categories are marked as contrasting. • If no word in C1 is antonymous to any word in C2, then the categories are considered not contrasting
Method • Degree of antonymy----category level • By distributional hypothesis of antonyms, we claim that the degree of antonymy between two contrasting thesaurus categories is directly proportional to the distributional closeness of the two concepts
Method • Degree of antonymy----word level • target words belong to the same thesaurus paragraphs as any of the seed antonyms linking the two contrasting categories highly antonymous • target words do not both belong to the same paragraphs as a seed antonym pair, but occur in contrasting categories medium antonymous • target words with low tendency to co-occur lowly antonymous
Method • Adjacency Heuristic • Most thesauri are ordered such that contrasting categories tend to be adjacent
Evaluation • 1,112 Closest-opposite questions designed to prepare students for GRE(Graduate Record Examination) • 162 questions as the development set • 950 questions as the test set
Evaluation • Closest-opposite questions • Ex: adulterate: a. renounce b. forbid c. purify d. criticize e. correct
Evaluation • Closest-opposite questions • Ex: adulterate: a. renounce b. forbid c. purify d. criticize e. correct 摻雜的 聲明放棄 禁止 純淨的 批評 正確
Discussion • The automatic approach does indeed mimic human intuitions of antonymy. • In languages without a wordnet, substantial accuracies may be achieved. • Wordnet and affix-generated seed are complementary.
Conclusion • Proposed an empirical approach to antonymy that combines corpus co-occurrence statistics with the structure of a thesaurus. • The system can identify the degree of antonymybetween word pairs. • An empirical proof that antonym pairs tend to be used in similar contexts.