Download

1 / 25
250 likes | 473 Views
Adaptive Optimization in the Jalapeño JVM. M. Arnold, S. Fink, D. Grove, M. Hind, P. Sweeney. Presented by Andrew Cove 15-745 Spring 2006. Research JVM developed at IBM T.J. Watson Research Center Extensible system architecture based on federation of threads that communicate asynchronously

E N D
Adaptive Optimization in the Jalapeño JVM M. Arnold, S. Fink, D. Grove, M. Hind, P. Sweeney Presented by Andrew Cove 15-745 Spring 2006
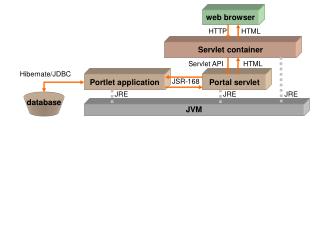
Research JVM developed at IBM T.J. Watson Research Center • Extensible system architecture based on federation of threads that communicate asynchronously • Supports adaptive multi-level optimization with low overhead • Statistical sampling Jalapeño JVM
Extensible adaptive optimization architecture that enables online feedback-directed optimization • Adaptive optimization system that uses multiple optimization levels to improve performance • Implementation and evaluation of feedback-directed inlining based on low-overhead sample data • Doesn’t require programmer directives Contributions
Written in Java • Optimizations applied not only to application and libraries, but to JVM itself • Boot Strapped • Boot image contains core Jalapeño services precompiled to machine code • Doesn’t need to run on top of another JVM • Subsystems • Dynamic Class Loader • Dynamic Linker • Object Allocator • Garbage Collector • Thread Scheduler • Profiler • Online measurement system • 2 Compilers Jalapeño JVM - Details
2 Compilers • Baseline • Translates bytecodes directly into native code by simulating Java’s operand stack • No register allocation • Optimizing Compiler • Linear scan register allocation • Converts bytecodes into IR, which it uses for optimizations • Compile-only • Compiles all methods to native code before execution • 3 levels of optimization • … Jalapeño JVM - Details
Optimizing Compiler (without online feedback) • Level 0: Optimizations performed during conversion • Copy, Constant, Type, Non-Null propagation • Constant folding, arithmetic simplification • Dead code elimination • Inlining • Unreachable code elimination • Eliminate redundant null checks • … • Level 1: • Common Subexpression Elimination • Array bounds check elimination • Redundant load elimination • Inlining (size heuristics) • Global flow-insensitive copy and constant propagation, dead assignment elimination • Scalar replacement of aggregates and short arrays Jalapeño JVM - Details
Optimizing Compiler (without online feedback) • Level 2 • SSA based flow sensitive optimizations • Array SSA optimizations Jalapeño JVM - Details
Sample based profiling drives optimized recompilation • Exploit runtime information beyond the scope of a static model • Multi-level and adaptive optimizations • Balance optimization effectiveness with compilation overhead to maximize performance • 3 Component Subsystems (Asynchronous threads) • Runtime Measurement • Controller • Recompilation • Database (3+1 = 3 ?) Jalapeño Adaptive Optimization System (AOS)
Sample driven program profile • Instrumentation • Hardware monitors • VM instrumentation • Sampling • Timer interrupts trigger yields between threads • Method-associative counters updated at yields • Triggers controller at threshold levels • Data processed by organizers • Hot method organizer • Tells controller the time dominant methods that aren’t fully optimized • Decay organizer • Decreases sample weights to emphasize recent data Subsystems – Runtime Measurement
A hot method is where the program spends a lot of its time • Hot edges are used later on to determine good function calls to inline • In both cases, hotness is a function of the number of samples that are taken • In a method • In a given callee from a given caller • The system can adaptively adjust hotness thresholds • To reduce optimization in startup • To encourage optimization of more methods • To reduce analysis time when too many methods are hot Hotness
Orchestrates and conducts the other components of AOS • Directs data monitoring • Creates organizer threads • Chooses to recompile based on data and cost/benefit model Subsystems – Controller
To recompile or not to recompile? • Find j that minimizes expected future running time of recompiled m • If , recompile m at level j • Assume, arbitrarily, that program will run for twice its current duration • , Pm is estimated percentage of future time Subsystems – Controller
System estimates effectiveness of optimization levels as constant based on offline measurements • Uses linear model of compilation speed for each optimization level as function of method size • Linearity of higher level optimizations? Subsystems – Controller
In theory • Multiple compilation threads that invoke compilers • Can occur in parallel to the application • In practice • Single compilation thread • Some JVM services require the master lock • Multiple compilation threads are not effective • Lock contention between compilation and application threads • Left as a footnote! • Recompilation times are stored to improve time estimates in cost/benefit analysis Subsystems – Recompilation
Statistical samples of method calls used to build dynamic call graph • Traverse call stack at yields • Identify hot edges • Recompile caller methods with inlined callee (even if the caller was already optimized) • Decay old edges • Adaptive Inlining Organizer • Determine hot edges and hot methods worth recompiling with inlined method call • Weight inline rules with boost factor • Based on number of calls on call edge and previous study on effects of removing call overhead • Future work: more sophisticated heuristic • Seems obvious: new inline optimizations don’t eliminate old inlines Feedback-Directed Inlining
System • Dual 333MHz PPC processors, 1 GB memory • Timer interrupts at 10 ms intervals • Recompilation organizer 2 times per second to 1 time every 4s • DCG and adaptive inline organizer every 2.5 seconds • Method sample half life 1.7 seconds • Edge weight half life 7.3 seconds • SPECjvm98 • Jalapeño Optimizing Compiler • Volano chat room simulator • Startup and Steady-State measurements Experimental Methodology
Results • Compile time overhead plays large role in startup
Results • Multilevel Adaptive does well (and JIT’s don’t have overhead)
Results • Startup doesn’t reach high enough optimization level to benefit
Assuming execution time will be twice the current duration is completely arbitrary, but has nice outcome (less optimization at startup, more at steady state) • Meaningless measurements of optimizations vs. phase shifts • Due to execution time estimation Questions
Does it scale? • More online-feedback optimizations • More threads needing cycles • Organizer threads • Recompilation threads • More data to measure • Especially slow if there can only be one recompilation thread • More complicated cost/benefit analysis • Potential speed ups and estimate compilation times Questions