Download

1 / 22
220 likes | 233 Views
A Reinforcement Learning Method Based on Adaptive Simulated Annealing. A uthored by: Amir F. Atiya Department of Computer Engineering Cairo University, Giza, Egypt Alexander G. Parlos Dept. mechanical Engineering Texas A&M University, College Station, Texas Lester Ingber

E N D
A Reinforcement Learning Method Based on Adaptive Simulated Annealing Authored by: Amir F. Atiya Department of Computer Engineering Cairo University, Giza, Egypt Alexander G. Parlos Dept. mechanical Engineering Texas A&M University, College Station, Texas Lester Ingber Lester Ingber Research Ingber.com September 13, 2003 Presented by Doug Moody, May 18, 2004 A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Glass-Blowing and its Impact on Reinforcement Learning • Considering the whole piece while focusing on a particular section • Slow cooling to relieve stress and gain consistency • Use of “annealing” A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Paper Approach • Review the reinforcement learning problem, and introduce the use of function approximation to determine state values • Briefly review the use of an adaptation of “annealing” algorithms to find functions that will determine a state’s value • Use this approach on a straight forward decision-making problem. A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Function ApproximationIntroduction • Much of our emphasis in reinforcement learning has treated a value function as one entry for each state-action pair • Finite Markov Decision processes have a fixed number of states and actions • This approach can, in some problems, introduce limitations when there are many states , insufficient samples across all states or a continuous state space. • These limitations can be addressed by “generalization” • Generalization also can be referred to as “function approximation” • Function approximation has been widely studied in many fields (think regression analysis!) A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Function ApproximationCharacteristics • A “batch” or “supervised learning” approach versus the on-line approach we have encountered • Requires a “static” training set from which to learn • Can not handle dynamically changing target functions, which may have been bootstrapped. • Hence , function approximation is not suitable for all types of reinforcement learning A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Function ApproximationGoals • Requires a “static” training set from which to learn • Can not handle dynamically changing target functions, which may have been bootstrapped. • Hence , function approximation is not suitable for all types of reinforcement learning • The value function is dependent upon a parameter vector which could be the vector of connection in a network • Typically function approximation wants to minimize: • P(s) are weights of the errors MSE: Mean Squared Error :vector of function parameters A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Function ApproximationMethods • Step by Step Approach : Gradient Descent - move slowly toward optimal “fit” • Linear Approach: Special case of Gradient where parameters are a column vector • Coding Methods • Coarse • Tile • Radial Basis Functions A Reinforcement Learning Method Based on Adaptive Simlated Annealing
COARSE CODING features should relate to the characteristics of the state For instance for a robot, the location, remaining power may be used For chess, the number of pieces, moves for pawn queen, etc.. Slide from Sutton and Barto textbook A Reinforcement Learning Method Based on Adaptive Simlated Annealing
LEARNING AND COARSE CODING Slide from Sutton and Barto textbook A Reinforcement Learning Method Based on Adaptive Simlated Annealing
TILE CODING • Binary feature for each tile • Number of features present at any one time is constant • Binary features means weighted sum easy to compute • Easy to compute indices of the features present Slide from Sutton and Barto textbook A Reinforcement Learning Method Based on Adaptive Simlated Annealing
RADIAL BASIS FUNCTIONS (GAUSSIAN) reflects degrees which feature is present Look to variance to show relationship of feature in the state space A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Paper’s Description of the Reinforcement Learning Model Basic System Value Definition Policy Definition Optimal Policy Eq. 4 Maximal Value Eq. 5 A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Value Function to Optimize weight parameter basis function GOAL: find the optimal set of that will lead to the most accurate evaluation A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Use Simulated Annealing to find best set of Wk • Annealing algorithms seek to search the entire state space and slowing “cool” to appropriate local minima • Algorithms trade off between fast convergence and continuous sampling of the entire • Used typically to find the optimization of a combinatorial problem • Requirements: • Concise definition of the system • Random generator of moves • Objective function to be optimized • Temperature schedule A Reinforcement Learning Method Based on Adaptive Simlated Annealing
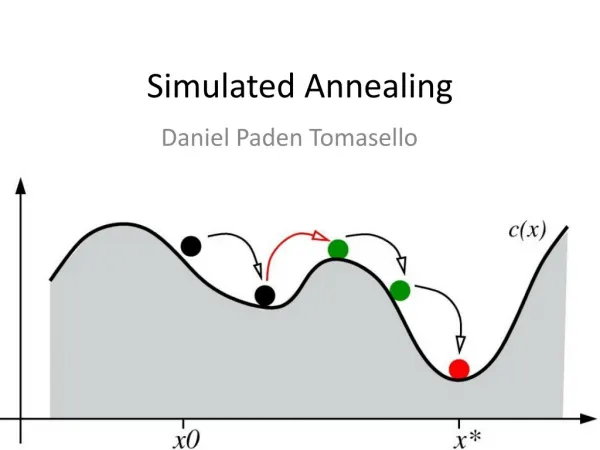
Example of Simulated Annealing • Problem - find the lowest valley in a mountainous region • View the problem as having two directions - North-South and East-West • Use a bouncing ball to explore the terrain at high temperature • The ball can make high bounces exploring many regions • Each point in the terrain has a “cost function” to optimize • As the temperature cools, the ball’s range and exploration decreases as it focuses on a smaller region of the terrain • Two distributions are used: generating distribution (for each parameter), acceptance distribution • Acceptance distribution determines whether to stay in the valley or bounce out. • Both distributions are affected by temperature A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Glass-Blowing Example • Larger changes are made to the glass piece at higher temperatures • As glass is cooled, the piece is still scanned (albeit more quickly) for stress points • Can not be “heated” up again and keep previous results A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Adaptive Simulated Annealing (ASA) • Has some approach as “simulated annealing” • Uses a specific distribution with a wider tail • Does not rely on “quenching” to achieve quick convergence • Has been available as a C programming system • Relies heavily upon a large set of tuning options: • scaling of temperatures , probabilities • limitation on searching in regions with certain parameters • linear vs. non-linear vector • Supports re-annealing - time is wound back ( and hence temperature) after some results are achieved to take example of found sensitivities • Good for non-linear functions More information and software available at www.ingber.com A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Reinforcement learning with ASA Search A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Sample Implementation • Problem: Choose the highest number from a sequence of numbers • Numbers are generated from an unknown source, with a normal distribution having a mean between 0 and 1 and a standard deviation between 0 and .5 • As time passes the reward is discounted • Hence the tradeoff: more waiting provides more information, but a penalty is incurred • Paper used 100 sources, with each generating 1000 numbers for a given sequence as the training set. A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Solution Approach • Define a state space as a combination of the following: • time t • the current mean at time t of observed numbers • the current standard deviation’ • the highest number chosen thus far • Place 10 Gaussian basis functions throughout the State Space • Use the algorithm to optimize a vector of weight parameters to the basis functions A Reinforcement Learning Method Based on Adaptive Simlated Annealing
RESULTS • ASA achieved an overall reward value • Q-Learning found the standard deviation • Improvement is substantial given that picking the first number in each set would yield .5 A Reinforcement Learning Method Based on Adaptive Simlated Annealing
Paper Comments • Pros • Looked to use existing reinforcement taxonomies to discuss the problem • Selected a straight forward problem • Negative • Did not fully describe the basis function placement • Insufficient parameter for Q-Learning used • Did not show an non-linear example • Could have provided more information on ASA Options used for results duplication A Reinforcement Learning Method Based on Adaptive Simlated Annealing